on
컴퓨터 구조 - 7
컴퓨터 구조 7강
KOCW 컴퓨터구조 2020-2학기 최규상 교수님 강의를 듣고 정리한 글이다.
Processor
이전에 컴퓨터 성능은 명령어 개수, clock cycle time, CPI 에 의해 결정된다는 것을 알았다. 그리고 compiler와 ISA가 프로그램에 필요한 명령어 개수를 결정한다. 여기서 clock cycle time, CPI 는 processor의 구현 방법에 따라 결정된다. 이제는 MIPS instruction set을 2가지 방법으로 구현하여 data path와 control unit을 완성시키려 한다.
Instruction Execution
- PC → instruction memory에
PC에 해당하는 주소로 가서 fetch instruction(명령어 읽어온다). - Register numbers → register file에 가서 register를 읽어온다.
- instruction의 종류에 따른 명령을 수행한다.
- Use ALU
- Load/Store data memory Access
- PC ← PC + 4
위 과정들을 아래의 그림과 같이 나타낼 수 있다.
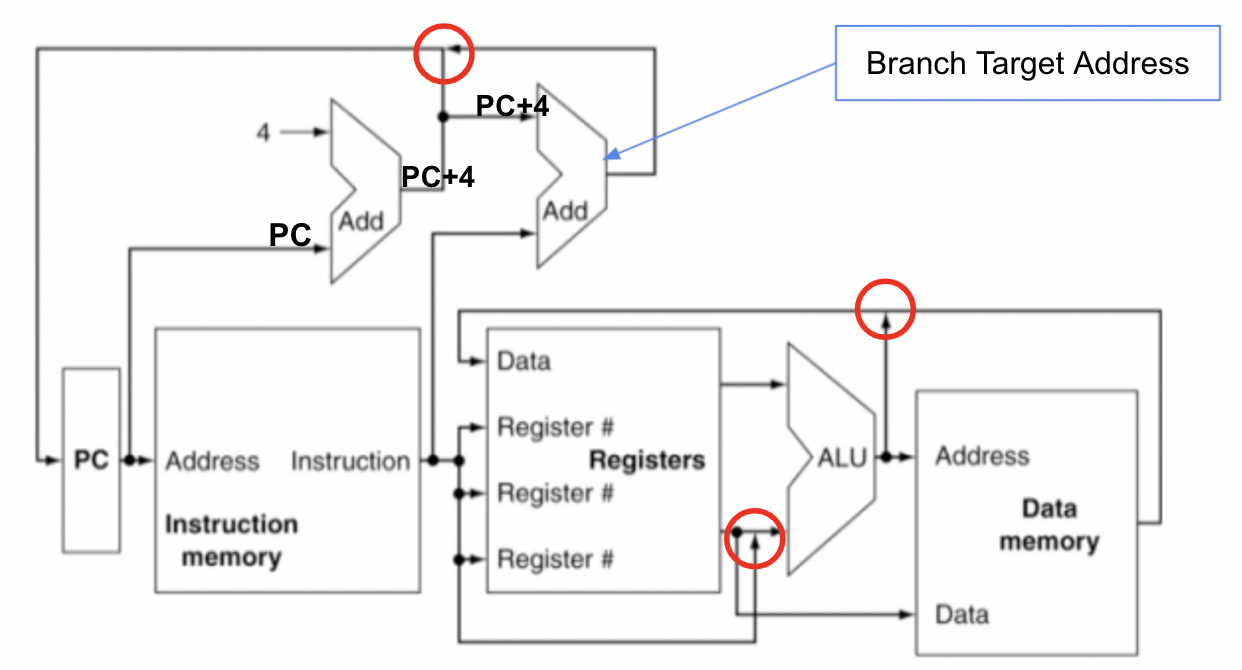
PC는 다음번 명령어를 가리키기 때문에 +4가 된 것을 볼 수 있다. 그러나 O라고 되어있는 곳을 보도록 하자. Hardware에서는 2개의 wire가 겹치는 경우는 없다. 따라서 위 그림으로 processor를 설계한다면 당연하게도 동작을 안할 것이다. → MUX를 사용해야 한다!!
그리고 Load, Store, Arithmetic instruction일 때 마다 unit이 다르게 제어되어야 하는데 그러한 기능을 하는 부분도 빠져있다.
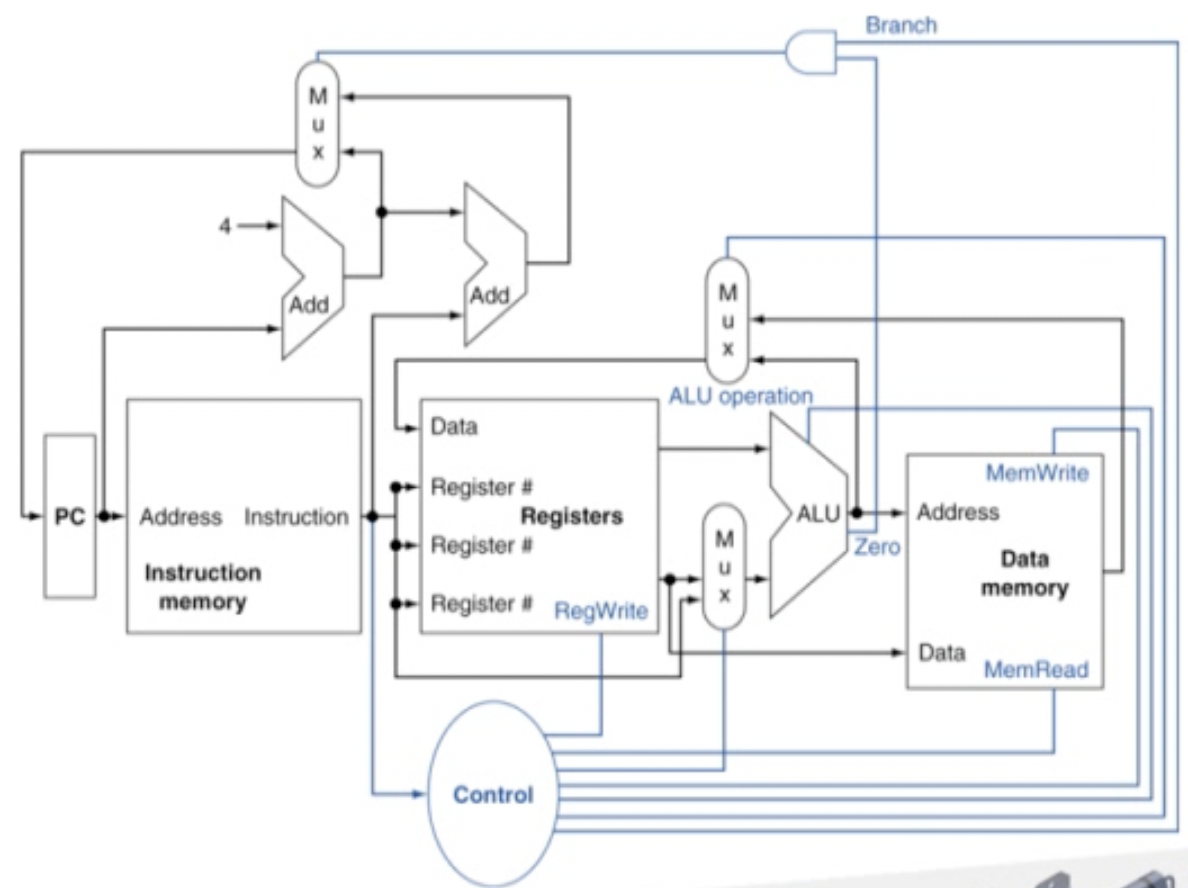
이렇게 MUX를 추가하여 MIPS subset의 기본적인 구현을 해볼 수 있다. Control은 CPU의 내부 구성요소들을 제어해주는 역할을 한다.
Clocking Methodology
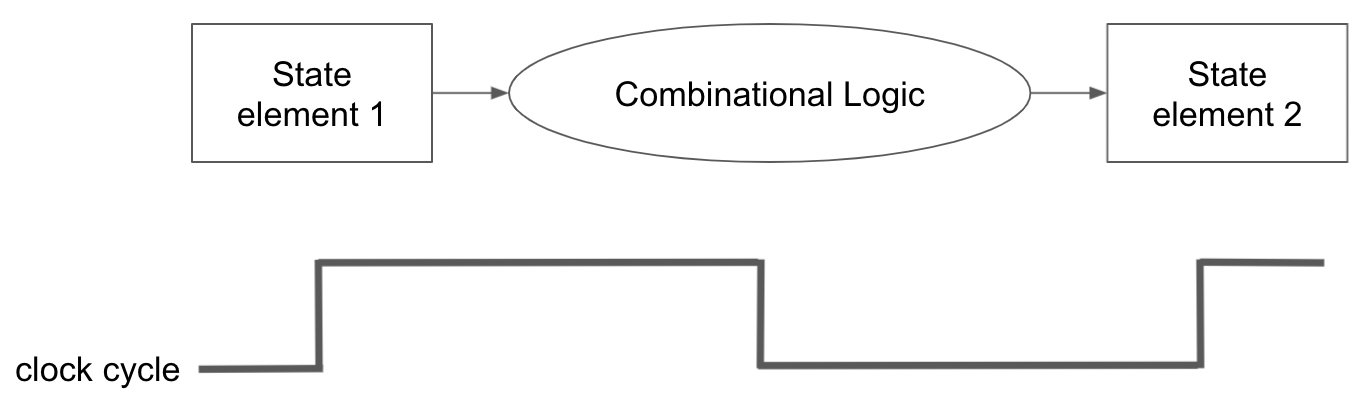
Sequential 회로는 edge-triggered clocking 방식을 가정한다고 하면, combinational logic에 input이 들어오면 해당 회로의 연산을 모두 마칠때까지 clock period가 보장이 돼야 한다. 따라서 가장 긴 delay를 가진 명령어에 clock이 맞춰지게 되는 것이다.
⇢ 이전 시간에 우리는 복잡한 명령어가 1개가 간단한 명령어 2~3개보다 더 오래걸린다고 했었다. 이 이유가 모든 명령어는 synchronize돼있기 때문에 가장 긴 clock period에 영향을 받게 되고, 복잡한 명령어는 clock period가 길기 때문에 더 오래걸리는 것이었다.
Processor의 3가지 구성요소
- Control
- Datapath
- Cache memory
우리는 1, 2를 간단하게나마 구현을 해볼 것이고, 3번은 나중에 구현하도록 할 것이다.
Datapath
process data와 address를 CPU에서 처리해주는 elements
datapath 설계를 시작하는 방법은 MIPS의 명령어 종류 각각을 실행하는데 필요한 주요 구성 요소들을 살펴보는 것. 각 명령어들이 어떤 datapath를 필요로 하는지 보도록 하자.
PC : program counter
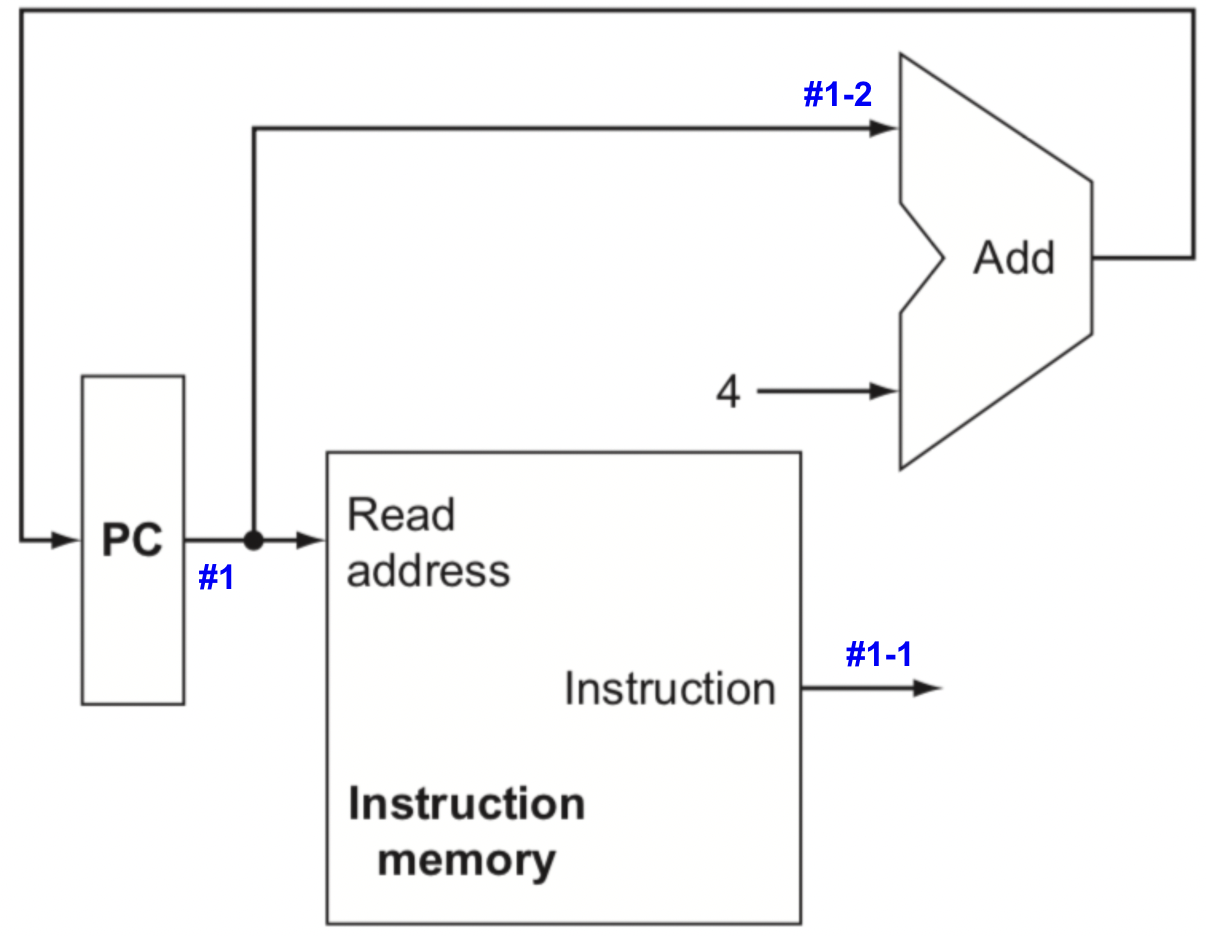
위 그림은 program의 명령어를 저장하고 주소가 주어지면 해당 명령어를 보내 주는 datapath 이다.
-
#1 : PC 현재 명령어의 주소를 갖고 있다.
-
#1-1 : 현재 명령어의 주소를 갖고, instruction memory에서 해당 주소에 맞는 instruction을 꺼낸 결과.
-
#1-2 : 다음번 명령어를 가리키기 위해
4와 ALU연산(더하기) 하는 것.-
Q1) 왜 4를 더하는 것인가?
일단 MIPS는 32bit system이다. 그리고 RISC 계열로써 모든 instruction의 길이가 32bit로 고정되어 있기 때문에 메모리의 4byte마다 다른 명령어가 있는 것이다. 따라서 다음번 명령어는 현재 명령어를 기준으로 4byte 후에 있는 것이므로 4를 더하여 다음번 명령어의 주소를 가리킨다는 것이다.
마찬가지로 64bit system에서는 8만큼 더하게 된다.
-
Q2) CISC에서는 왜 명령어의 길이가 고정되지 않았는가? - 참고한 자료
예전에는 program의 용량이 매우 중요했다고 한다. 따라서 1개의 최소 명령어 길이로 최대의 동작을 하게 했어야 했었다. 따라서 1~15byte로 명령어의 길이가 가변적인 것이다. → CISC는 RISC보다 메모리 사용에 있어서 더 효율적. 같은 메모리에 더 많은 명령어를 집어넣을 수 있기 때문.
-
R-format Instruction
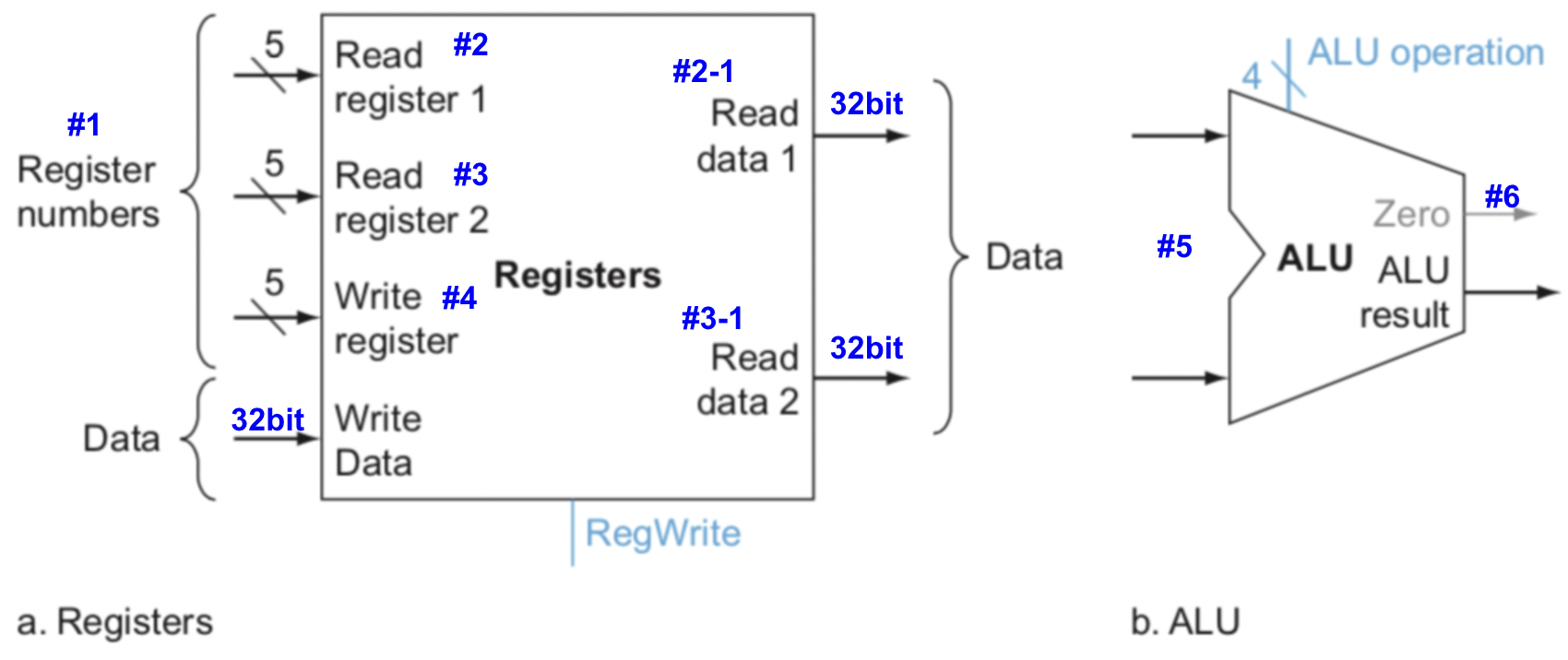
- #1 : 위의 PC값에 의해 나온 현재 명령어가 input으로 들어온다.
- #2 : source register의 주소값. MIPS는 32개의 register를 쓰기 때문에 5bit로 32개라는 숫자를 표현할 수 있다.
- #2-1 :
#2에서의 register에 대한 value.
- #2-1 :
- #3 : target register의 주소값.
- #3-1 :
#3에서의 register에 대한 value.
- #3-1 :
- #4 : destination register의 주소값.
- #5 :
#2-1, #2-2의 결과를 ALU연산한다. - #6 :
zero는#5에서의 연산 결과가 0인지 판단해준다. 연산의 결과가 0이면 1을 출력하고 아니면 0을 출력한다. - Write Data :
#6ALU연산의 결과를 destination register에 저장하게 될 때, 저장되는 data.
예시를 한번 들어보도록 하자. 아주아주 간단한 add연산이다.
add $t0, $s0, $s1 # $s0: 4, $s1: 6
MIPS register 32개는 각각의 register number가 있는것을 우린 배웠다. $t0: reg 8, $s0: reg 16, $s1: reg 17이다. 따라서 #2부분에 16이라는 register number가 들어가고, #3에는 17이라는 값이, #4의 주소에는 #2, #3의 ALU연산의 결과가 저장될 register number인 8이 들어가게 된다.
#2-1에는 $s0가 갖고 있는 4라는 값이 나오고, #3-1에는 $s1이 갖고 있는 6이라는 값이 나오게 된다. ALU연산의 결과값인 4+6=10은 #4의 register에 write된다. add연산이라는 것은 ALU Operation이 결정해준다. 물론 register에서 write/read는 RegWrite의 값에 따라 결정된다.
Load/Store Instruction
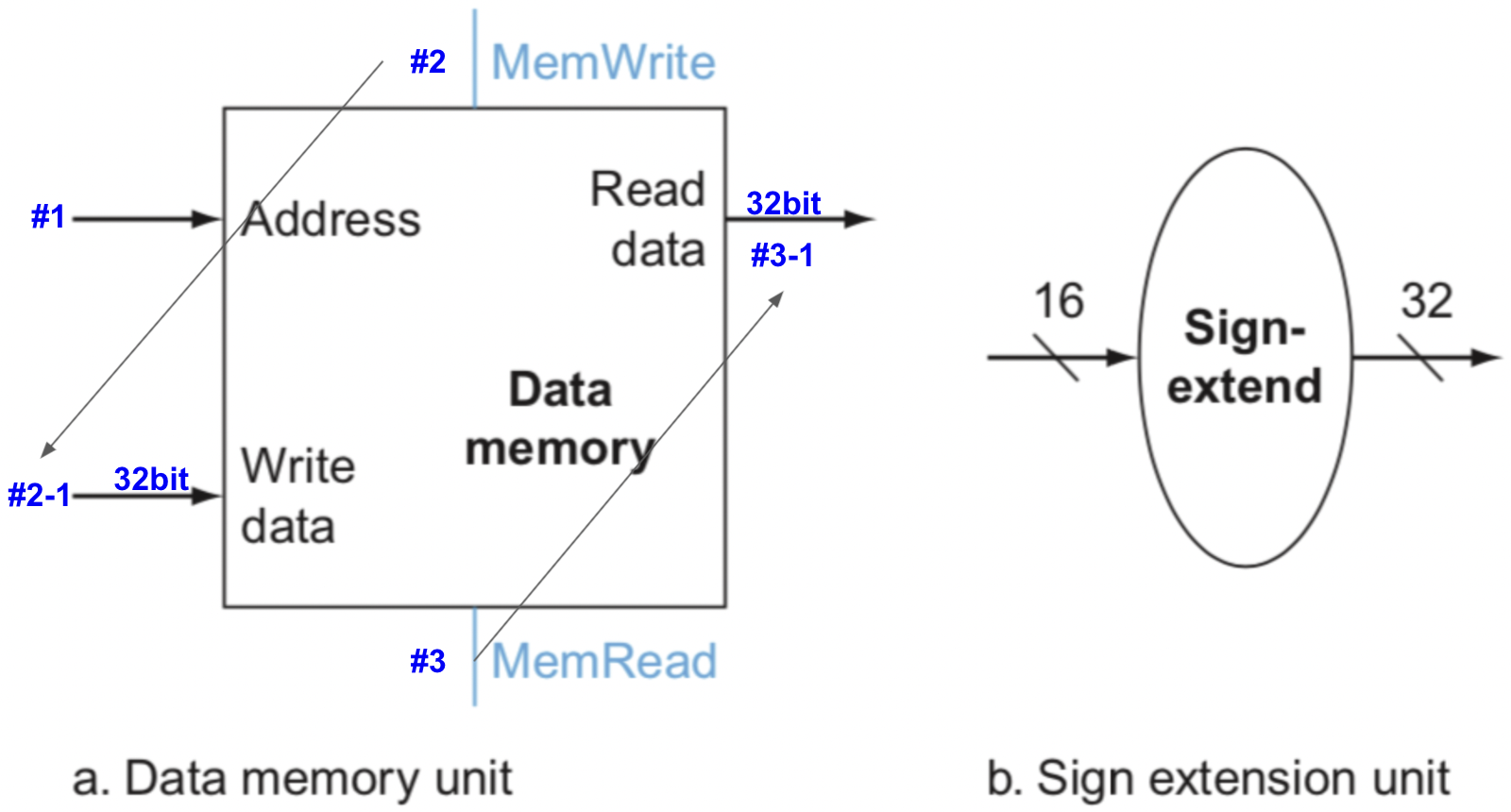
-
a - data memory unit
- #1 : 아까 위에서 봤던
R-format instruction의 ALU연산의 결과가 input으로 들어온다. - #2 : memWrite=1이라면,
- #2-1 :
#1에 들어온건 메모리의 주소이다. 해당 메모리의 주소에 write data를Store.
- #2-1 :
- #3 : memRead=1이라면,
- #3-1 : 해당 메모리의 주소에 있는 값을 Read data로
Load.
- #3-1 : 해당 메모리의 주소에 있는 값을 Read data로
- #1 : 아까 위에서 봤던
-
b - sign memory unit
lw, sw는 I-type Instruction이다. 그 때 offset(address)는 16bit이기 때문에 32bit가 되도록 sign-extend를 해주는 것.
Branch Instruction
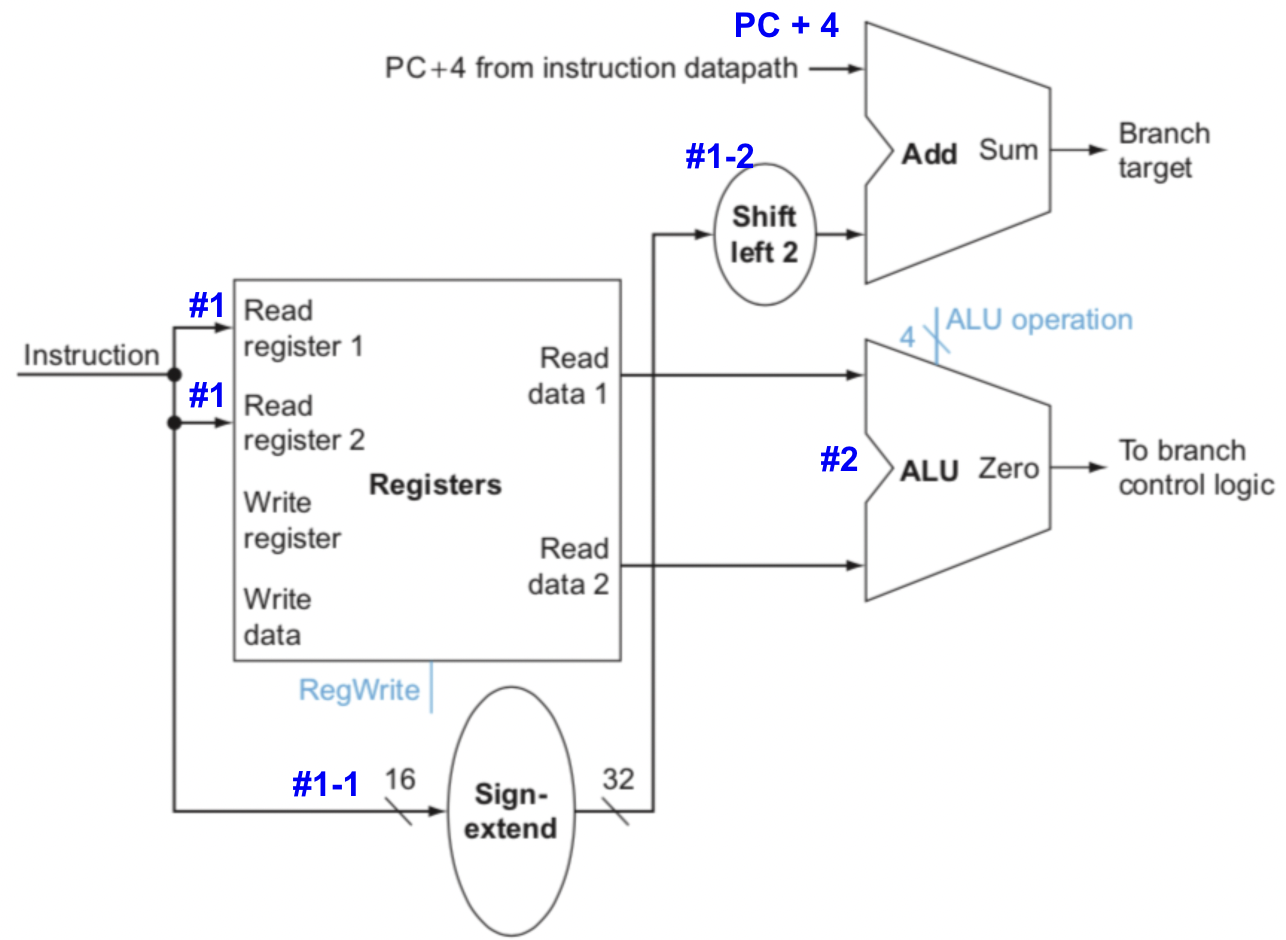
- #1 : IF에 의해 나온 결과인 Instruction에 해당하는 register 주소 2개.
- #1-1 : branch 명령어에서는 하위 16bit가 address를 표현한다. (더 정확히는 address를 표현하기 위한 offset으로 사용된다.) 따라서
Label에 해당하는 주소로 가기 위해 PC값과 add연산을 해야하는데 PC는 32bit이다. 그래서 sign-extend를 하여 32bit로 확장시켜주는 것. - #1-2 : 말 그대로 offset 역할을 하기 때문에 base address로부터 해당 Label이 얼만큼 떨어져 있는지를 나타내준다. 이 때 base address는 PC+4(다음번 명령어 주소를 가리킴)이고, MIPS는 32bit(==4byte)가 1word이므로 offset에 4만큼 곱해주고
PC+4와 더하기 연산을 해줌으로써 Label의 주소를 표현해준다. shift left를 2번하면 4만큼 곱한 것과 같다.
- #1-1 : branch 명령어에서는 하위 16bit가 address를 표현한다. (더 정확히는 address를 표현하기 위한 offset으로 사용된다.) 따라서
- #2 : 2개의 register 값이 같냐, 다르냐에 따라서 다음번의 명령어가 달라진다. (
PC+4orPC+4 + offset*4)
Full Datapath
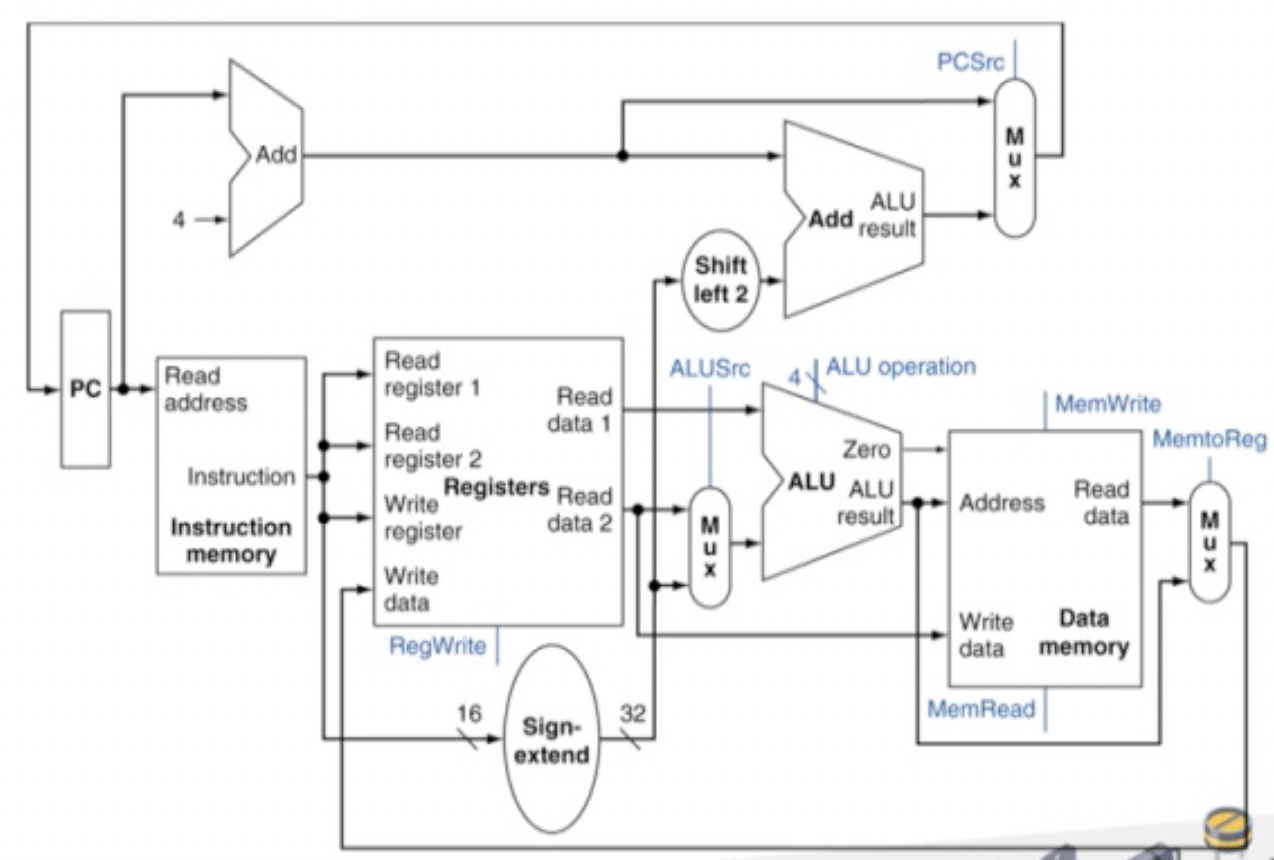
단순화시킨 datapath를 완성했다. 이제 control unit을 추가해야 한다. → 각 MUX의 신호, ALU 제어를 하기 위해서이다.
ALU Control
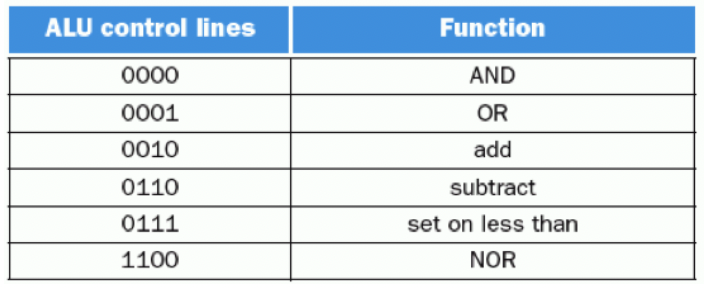
MIPS ALU는 입력 4개를 사용하는 위 6가지 조합을 정의하고 있다.
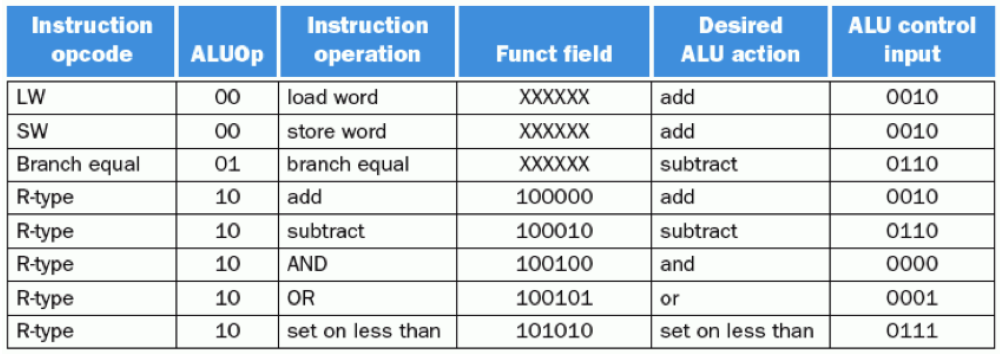
ALU control bit들은 ALUOp control bit와 R-format instruction의 funct 코드값에 의해 결정된다. Kocw 3강에서 우리는 R-format에 대해 배웠었다. 그 때는 add, sub 등등의 연산을 구별해주는게 funct 코드라고 듣기만 했었는데 이렇게 직접 보게 된 것이다.
lw, sw는 Load/Store 명령어이기에 I-format을 사용한다. 따라서 funct code가 없으므로 xxxxxx로 돼있는 것이다.
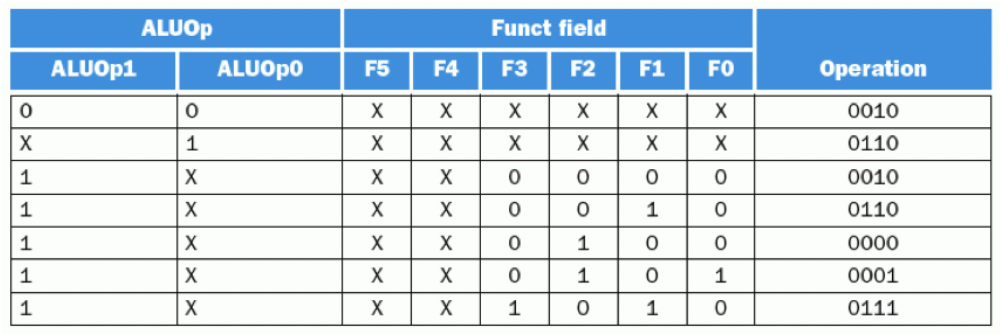
결론적으로 2bit의 ALUOp, 6bit의 funct code(field)를 4bit의 ALU control bit로 mapping시켜서 제어하는 것이다. 그리고 이 회로를 설계하기 위해서는 기본적으로 combinational circuit이므로 truth table을 만드는게 좋다. 위의 표를 토대로 만들면 아래와 같다.
Datapath with Control
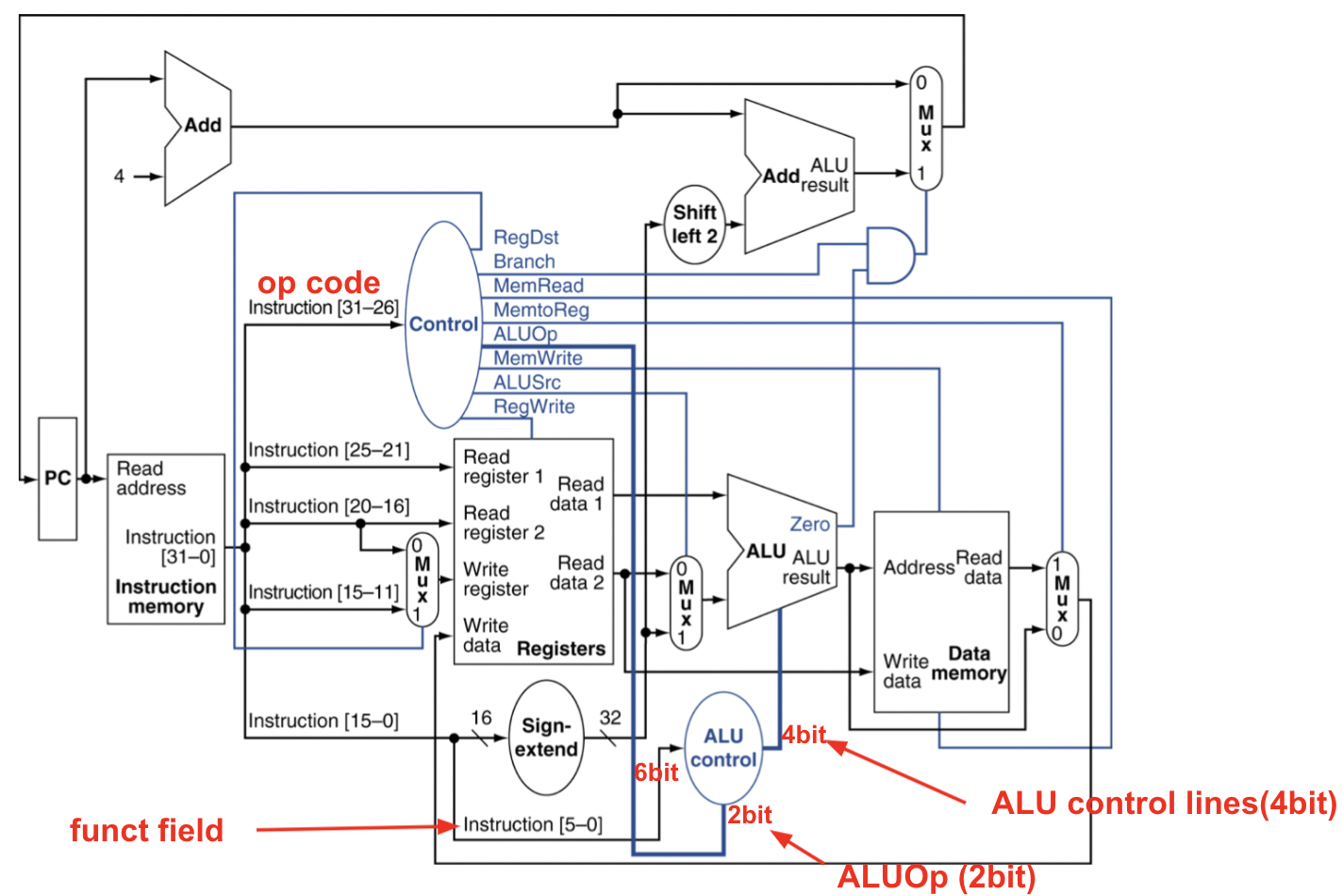
이제 제법 복잡해진게 느껴질 정도다. 하지만 subset unit의 기능을 하나하나 이해하고 넘어갔다면 그저 그것들을 붙여놓은 것뿐이기에 똑같은 것이라고 생각한다.
Performance Issue
-
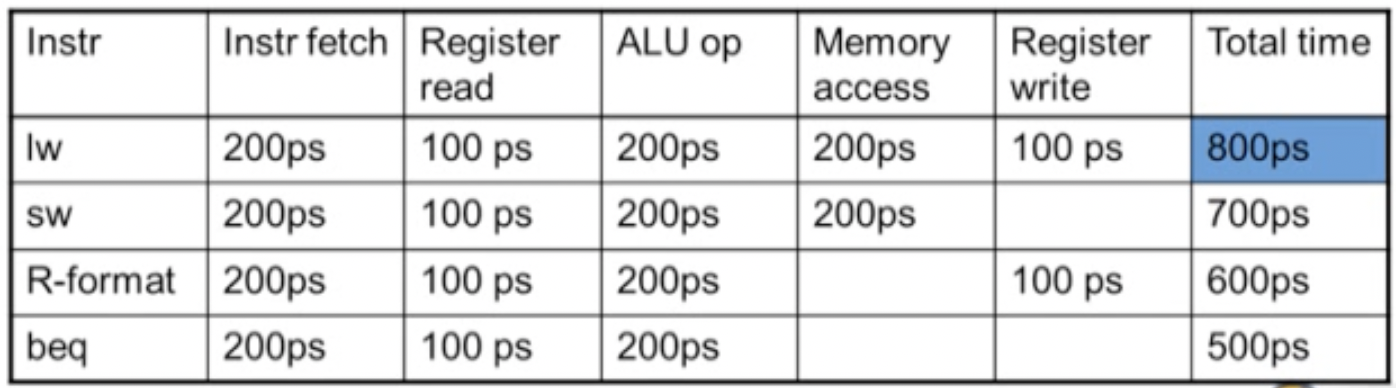
가장 긴 delay를 가진 명령어가 clock period를 정한다
→
lw가 가장 길었다. instruction memory Access → register file Access → ALU → data memory Access → register file Access 라는 과정을 거치기 때문에 오래걸린다. -
각각의 명령어에 대해서 각각 다른 clock period를 사용하는 것은 어렵다. clock을 어떤 명령어를 수행할 땐 빠르다가 어떤 명령어를 수행할 때는 느리게 할 수 없다는 것이다.
-
clock은 delay가 가장 긴
lw에 모두 동기화되어 있다. 근데lw는 그렇게까지 자주 사용하는 명령어는 아니다. 이는 MIPS의 설계원칙 중 하나인 Make the common case fast를 위반했다. → pipeline방식 채택한 이유.
Pipeline
pipelining은 여러 명령어가 중첩되어 실행되는 구현 기술이다. 지금까지 구현한 간단한 MIPS processor는 1 clock에 1개의 instruction을 처리했었다.이제는 pipelining으로 병렬적으로 처리하는 방법을 배워보도록 하자.
MIPS Pipeline
IF: Instruction Fetch from memoryID: Instruction Decode & Register readEX: Execution operation OR Calculate AddressMEM: Access memory operands. data memory에 접근하는 것WB: Write Back. 결과를 다시 register에 write
MIPS Pipeline
아까 말했듯이 lw명령어가 가장 오래 걸림을 알 수 있었다.
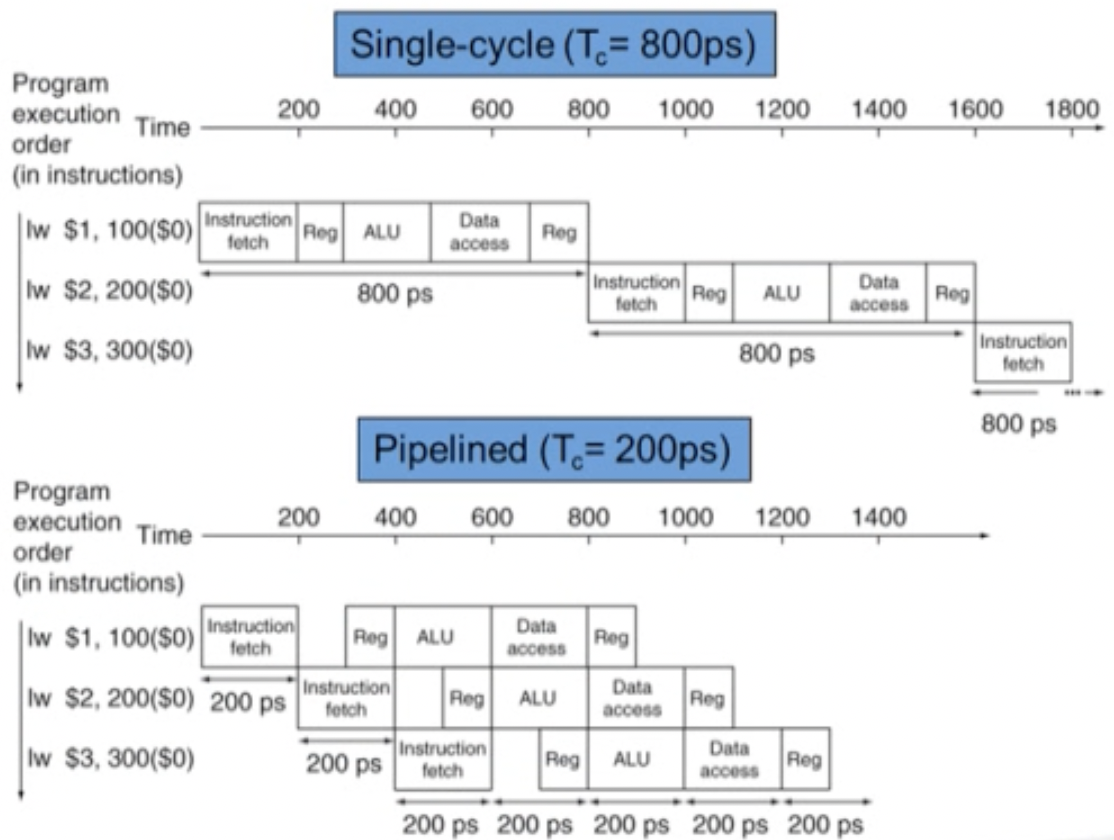
위 그림을 보면, lw명령어를 pipelining을 했을 때와 안했을 때의 실행시긴의 차이를 알 수 있다. 3번의 load instruction을 실행하는 동안 pipelining이 아닐 때에는 2400ps가 걸렸고, 했을 때에는 1400ps가 걸림으로써 성능향상을 볼 수 있다.
Pipeline Speed up
- 만약 모든 stage가 같은 시간이 걸린다면, 명령어 사이의 시간은 non-pipelined time/stage수 이다.
- 하지만 모든 stage 시간이 같은 이상적인 상황은 거의 없다. 따라서 이상적인 상황보다 속도가 느려지게 된다.
- 우리는 이때까지 response time을 줄여서 성능을 향상시키는 것을 배웠지만, pipeline은 througput을 증가시켜 성능을 향상시킨다. pipeline을 사용하게 되면 response time은 늘어날지 몰라도 1개의 명령어를 수행하는데 시간이 줄어들기 때문에(througput증가) 성능이 향상되는 것.