on
운영체제 - 8
KOCW 운영체제 8강
양희재 교수님 강의를 듣고 쓴 글입니다.
SJF(Shortest-Job-First)
CPU Time을 가장 적게 쓰는 process를 우선적으로 Ready Queue에서 꺼내서 CPU Time을 할당해주는 스케쥴링 알고리즘이다.
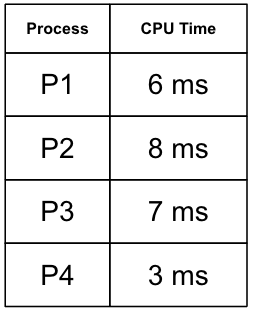
위와 같은 예시가 있다고 해보자. 위 경우에서 SJF 알고리즘으로 AWT(Average Waiting Time)을 구해보도록 할 것이다. P1~P4는 모두 0ms에 Ready Queue에 도착했다고 하자.

CPU Time이 짧은 순서대로 Queue에서 선택되므로 위와 같이 처리된다.
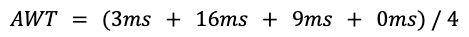
AWT를 계산하면 7ms가 나옴을 알 수 있다.
3ms: P1의 대기시간.16ms: P2의 대기시간.9ms: P3의 대기시간.0ms: P4의 대기시간. P4는 들어오자마자 실행됐기 때문에 대기시간이 0이다.
만약 FCFS(First-Come, First-Server)로 AWT를 구한다면?
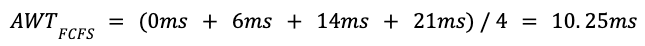
결론 : SJF는 optimal하다. 하지만 현실적이지 않은 알고리즘이다. → 실제로 해당 process가 CPU Time을 얼마나 사용할지 아무도 모르기 때문이다. 따라서 예측해야 하는데 이러한 과정들이 overhead가 될 수 있다.
Non-preempitive SJF
Non-preempitive는 process가 CPU에 실행되고 있으면, 끝날 때까지 기다려야 한다.
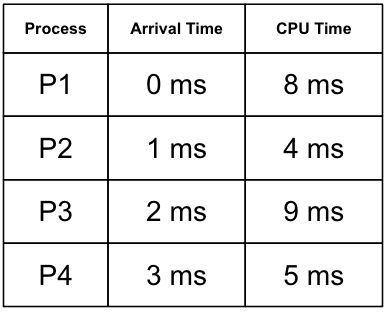
위와 같은 예시상황이 있다고 해보자.
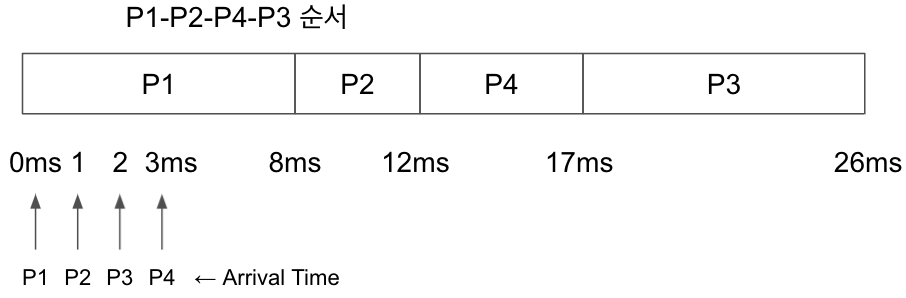
이번엔 P1~P4가 같은 시각에 Queue에 도착한 것이 아니라 다른 시각에 도착한 상황이다. Non-preempitive SJF 로 process 처리순서를 나타내면 위와 같다. 원래라면 SJF이므로 가장 CPU Time이 짧은 P2가 먼저 처리됐어야 했지만 P1보다 늦게 도착했기 때문에 P1이 먼저 처리되는 모습을 볼 수 있다. 그리고 Non-preempitive하므로 P1이 모두 다 처리된 후에 P2가 처리될 수 있었다.
이제 AWT를 구해보자.
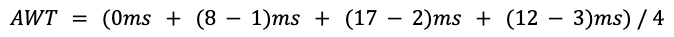
7.75ms가 나온다. 아까와는 달리 수식이 약간 더 복잡해 보인다. Queue에 도착한 시각이 다르기 때문에 대기 시간도 아까와는 다르게 계산해야했기 때문이다.
0ms: P1은 0ms에 들어왔다. 그 때 Queue에는 P1밖에 없으므로 바로 CPU에 의해 처리된다. 따라서 대기시간 0ms.(8-1)ms: P1이 다 실행될 때까지 기다린 시점에서 P2~P4는 모두 Queue에 존재한다. 그 때 SJF에 따라서 P2의 CPU Time이 가장 짧으므로 처리된다. P1을 처리하는데 8ms가 걸렸고, P2는 1ms에 Queue에 들어왔기에 대기시간은(8 - 1)ms가 된다.(17-2)ms: 가장 우선순위가 마지막이었던 P3이다. 따라서 P1, P2, P4가 모두 끝났을 때는 17ms. P3는 2ms에 Queue에 들어왔기에 대기시간은(18 - 2)ms가 된다.(12-3)ms: 마찬가지로 대기시간은 P2가 끝났을 때 시각과 P4가 Queue에 들어왔을 때 시각을 뺀 값이 된다.
Preempitive SJF
아까 위에서와 같은 예시이다. AWT를 구해보자.
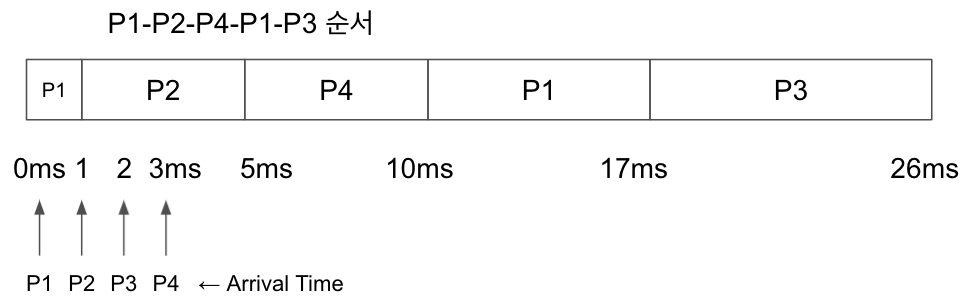
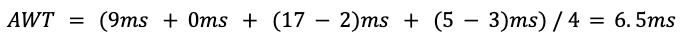
같은 상황에서 더 짧은 AWT가 나왔다!
9ms: P1이 먼저들어오고 1ms 후에 우선순위가 더 높은 P2가 들어왔다. 따라서 첫 대기시간은 0ms. 이후에 P1에게 우선순위가 왔을 때 기다렸던 시간은 9ms이다.0ms: P2가 Queue에 올라오자마자 가장 높은 우선순위를 부여 받아서 P1을 내보내고 CPU Time을 쓰게 됐다. 이후로 Queue에 loading된 P3, P4보다도 우선순위가 높았기에 그대로 CPU가 처리한 것. 따라서 대기시간은 0ms.(17-2)ms: 아까와 마찬가지의 상황. 우선순위가 가장 낮았기에 Queue에 올라온 모든 process가 끝난 뒤에 처리됐다.(5-3)ms: P2 다음으로 우선순위가 높았기에 P2가 끝나던 시각 5ms에 Queue에서 CPU가 처리했다. 3ms에 load됐기 때문에 대시시간은 2ms.
이렇듯 어떤 방식으로 process를 처리하냐에 따라 효율성이 달라진다.
Priority Scheduling
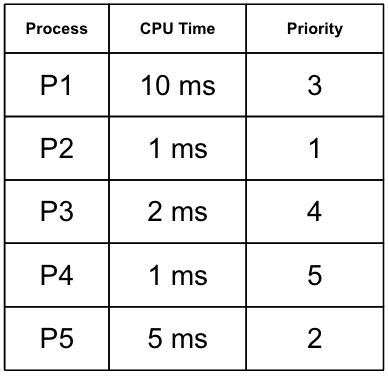
Priority의 숫자가 작으면 더 높은 우선순위를 가진다고 하자.
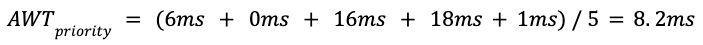
AWT는 위와 같이 계산될 것이다.
Starvation
Queue에 있는 우선순위가 낮은 process가 하나 있다고 가정해보자. 해당 process보다 높은 우선순위의 process들이 Queue에서 사라지면, 언젠간 CPU에 의해 처리될 것이다. 하지만 만약에 미처 높은 우선순위의 process들이 다 사라지기도 전에 새로운 process(우선순위가 더 높음)가 Queue에 load된다면? 이라는 상황을 가정해보자. 아마도 우선순위가 낮은 그 process는 영원히 실행되지 못한채로 Queue에 남을 것이다. 결국 CPU Time을 못 받는다는 것이다. 이를 가리켜 Starvation이라고 부른다.
해당 현상은 Aging이라는 것으로 해결한다. 시간이 지남에 따라 우선순위에 변화를 주면서 말이다.
Round Robin
Time-Sharing System- Time Quantum == Time Slice 단위로 process 처리.
- Preempitive scheduling
Time Slice(=𝝙)로 시간을 쪼개서 매번 process를 처리한다.

𝝙=4ms라고 가정했고, 상황은 위와 같다.

Round Robin방식으로 process를 처리한 과정이다. 𝝙를 어떻게 하냐에 따라서 AWT는 달라진다. 따라서 성능이 𝝙에 의존적이다.
- 만약 𝝙 → ∞ 라면,
Round Robin→FCFS가 될 것이다. - 만약 𝝙 → 0 이라면,
context-switching이 너무 자주 일어나서 시스템에 overhead를 줄 것이다.
따라서 적절한 𝝙를 찾는게 성능에 중요하다.