on
운영체제 - 9
KOCW 운영체제 9강
양희재 교수님 강의를 듣고 쓴 글입니다.
Multilevel Queue Scheduling
이전에는 process의 구분없이 Queue에서 기다렸다가 어떠한 알고리즘에 의해 CPU Time을 받았다. 근데 잘 생각해보면, process는 공통적인 특성을 가진 group화가 될 수 있을 것이다.
- Process Group
- System process : OS가 관리하는 시스템 process → 시스템 요소는 중요하기 때문에 우선순위가 높아야 한다.
- Interactive process : 상호작용을 하는 process. → 상호작용은 그 때 그 때 바로바로 돼야 하므로 우선순위가 높다.
- Interactive editing process : word 와 같은 상호작용을 하는 편집기.
- Batch process : 상호작용 없이 컴퓨터가 적당히 알아서 일괄적으로 처리하는 process. → 지금 당장 처리해야하는 일보다는 우선순위가 낮다.
- Student process… 등등
이런식으로 process 별로 특성을 묶어서 그룹화를 할 수 있다. 그렇다면 의문이 들 것이다.
➡ 우리는 왜 이전까지 Queue를 하나만 썼는가?
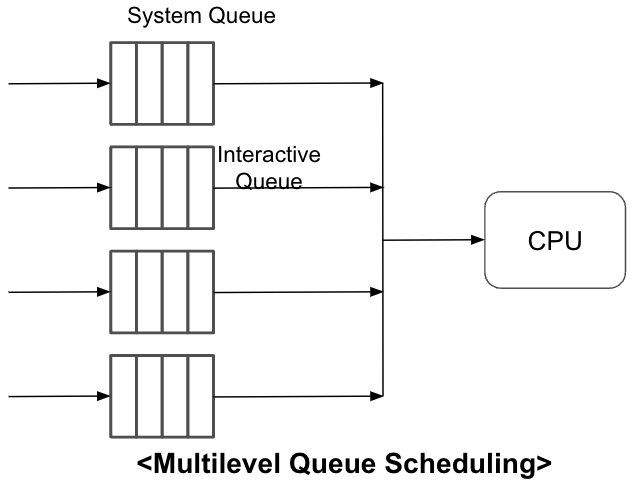
Queue를 1개가 아니라 여러개를 둬서 process의 schedule을 관리하는 것을 Multilevel Scheduling이라고 한다.
그렇다면 왜? 굳이? 여러개의 Queue를 사용하는 것일까?
- 서로 다른 Scheduling Algorithm 적용 가능.
- Queue마다 CPU Time 다르게 할당 가능.
이라고 본 강의에서는 말하고 있다.
Multilevel Feedback Queue Scheduling
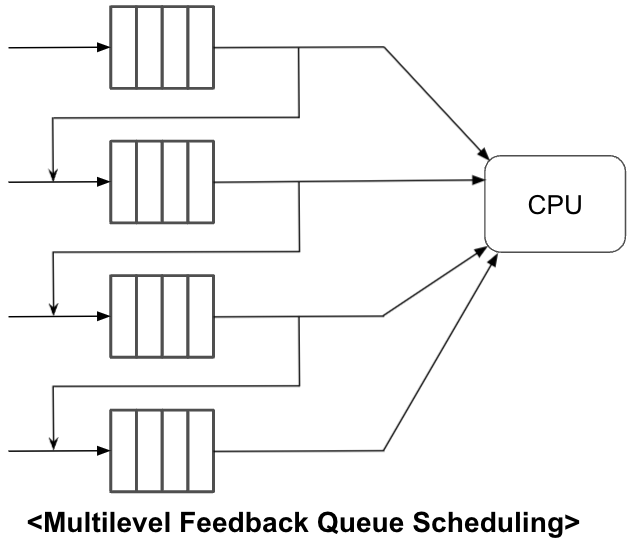
같은 Queue에만 계속 있는게 아니라 다른 Queue로의 점진적 이동이 가능하다.
→ 너무 많은 CPU Time 사용시 다른 Queue로 가게 할 수 있다. 또는 starvation 우려 시 우선순위가 높은 Queue로 보낼 수 있다.
오늘날 실제 우리가 쓰는 OS에는 앞서 소개했던 거의 모든 알고리즘들을 쓴다고 한다.
Process Creation
process는 process에 의해 만들어진다.
다시 복습해보는 컴퓨터 부팅 시 동작!
- 컴퓨터 전원을 ON!
- HDD/SSD에 있는 OS가 main memory로 loaded.
- 그 다음에 OS는 제일 먼저 첫번째 process를 만든다.
init이라는 이름의 process를 만든다고 한다. (OS마다 이름은 다를 수 있다고 한다.)
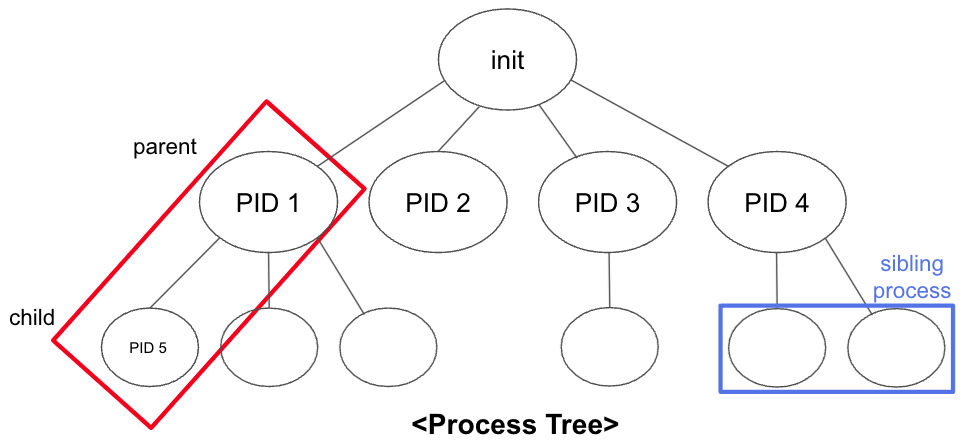
이런식으로 init으로 부터 다른 process가 만들어진다.
- PID(Process Indentifier) : OS kernel이 사용되는 번호. PID를 통해 어떤 process를 특정할 수 있다.
- PPID(Parent Process Indentifier) : 부모 PID
Thread
program 내부의 맥, 흐름. 하나의 program엔 적어도 하나의 thread가 있다.
Multi-Thread
어떻게 동작할까?
→ Thread가 빠른 시간 간격으로 스위칭 된다. == 여러 Thread가 동시에 실행되는 것처럼 보인다. (실제로는 1번에 1개씩만 실행 중 concurrent)
예를 들면,
- Web browser : 화면 출력 Thread + data read Thread
- Word : 화면 출력 Thread + 키보드 입력 Thread + 맞춤법 확인 Thread
과 같은 경우이다. 현대의 거의 모든 program은 multi-thread 방식으로 동작된다.
따라서 context-switching의 단위는 이제부턴 process가 아니라 thread가 된다.
Thread는 같은 process 내에서 data + code 를 공유하고, Stack, register, PC, SP 등은 공유를 안한다.