on
JAVA - Multi-Thread Programming
Java
Java 공부를 정리 tag
Multi-Thread Programming
Thread
process 내에서 실행되는 단위. - wiki
1개의 프로세스는 적어도 1개의 thread를 가진다. 그리고 하나의 프로세스 안에서 2개 이상의 thread가 동시에 실행될 수 있는데 이를 multi-threading이라고 한다.
Process
컴퓨터의 메모리에 올라가서 실행되는 프로그램을 뜻한다.
여러개의 프로세스를 사용하는 것을 multi-processing이라고 하며, 같은 시간에 여러개의 프로그램을 띄우는 방식을 multi-tasking이라고 한다.
- program : Storage에 저장되어 있는 실행코드.
- process : program이 메모리에 올라와 실행되는 상태.
Thread vs Process

Multi-Processing, Programming, Threading
-
Multi-Processing : 하나 이상의 프로세스가 서로 협력하여 일을 처리. 각 프로세스가 독립적으로 실행됨. 각각 별개의 메모리를 가진다. 작업이 간단한 경우에는 상관 없지만, 많은 작업을 빠른 시간에 처리하기 위해서는 하나의 프로세서가 처리하는 것은 보다 많은 시간을 요구.
- 장점 : 어떤 프로세스에 문제가 생겨도 다른 프로세스에 영향을 주지 않는다.
- 단점
context-switchingoverhead : 프로세스는 각각의 독립된 메모리 공간을 할당받기 때문에 프로세스 간의 공유하는 메모리가 없다. 따라서context-switching이 발생하면 많은 시간이 걸리게 된다.
-
Multi-Programming
초기의 컴퓨터는 하나의 작업만 실행될 수 있었다. 어떤 작업을 하고 있다면, 다 끝날 때까지 다른 작업을 할 수 없었는데 processor의 처리 속도와 I/O device의 처리속도의 차이가 컸기 때문에 processor가 I/O device의 속도를 기다려줘야만 했다. 이는 자원 낭비의 원인이었고, 따라서 I/O 작업동안 processor가 대기하는 시간을 다른 프로그램을 실행시키는데 사용하게 되도록한게
multi-programming이다. 현대의 OS는 대부분multi-programming system이다. -
Multi-Threading : 하나의 프로세스 내에서 생성되는 하나의 실행 단위. 프로세스 내 메모리 공유가 가능. thread간의 전환속도가 프로세스간의 전환속도보다 빠르다.
-
장점
-
시스템 자원 소모 감소 (자원의 효율성 증대) 프로세스를 생성하여 자원을 할당하는 시스템 콜이 줄어들어 자원을 효율적으로 관리할 수 있다.
-
시스템 처리량 증가 (처리 비용 감소)
- 스레드 간 데이터를 주고 받는 것이 간단해지고 시스템 자원 소모가 줄어들게 된다.
- 스레드 사이의 작업량이 작아 Context Switching이 빠르다.
-
간단한 통신 방법으로 인한 프로그램 응답 시간 단축
스레드는 프로세스 내의 Stack 영역을 제외한 모든 메모리를 공유하기 때문에 통신의 부담이 적다.
-
-
단점
-
프로세스가 죽으면 다 같이 종료된다.
-
동기화 문제가 발생할 수 있다.
-
하나의 thread에 문제가 발생하면 프로세스 전체에 영향을 미친다.
-
어떤 thread가 먼저 실행될지 알 수가 없기 때문에 디버깅이 까다롭다.
→
semaphore를 사용하여 공유자원에 접근하는 thread의 수를 제한해서 해결할 수 있다.
-
-
Multi-Processing vs Multi-Threading
왜 multi-threading을 더 많이 사용하게 될까?
-
자원의 효율성 증가
multi-processing으로 실행되는 작업을multi-threading으로 실행할 경우, process를 생성해야하는 system call이 줄어들어서 자원을 효율적으로 관리할 수 있다. -
처리비용 감소
multi-threading은 stack영역을 제외하고 프로세스 내 메모리를 공유하기 때문에context-switching이 발생했을 때 overhead가 더 적다. 따라서 전환속도가 더 빠르기에 좋다. -
그러나 동기화 문제를 조심해야 한다.
Java Multi-Thread
Java JDK 8 Concurreny를 보고 정리하는 글입니다.
Concurrency
Even the word processor should always be ready to respond to keyboard and mouse events, no matter how busy it is reformatting text or updating the display. Software that can do such things is known as concurrent software.
Java는 concurrent programming을 염두하며 만들어졌다. 이 문서로 우리는 java.util.concurrent package를 배워볼 것이다.
concurrent programming에서 2개의 실행 단위가 존재한다.
-
Process
Self-contained 실행환경. 완전한 run-time resource set이 있다. 각 프로세스는 각각의 메모리 영역이 있다. 프로세스 간의 통신을 위해 OS는 IPC를 지원한다. Java에서는
ProcessBuilderclass를 사용하여 프로세스를 생성할 수 있다. 하지만 thread라는 주제에 벗어나기 때문에 여기에선 안 다룬다고 한다. -
Thread
Light-weight process라고도 불린다고 한다. 새로운 thread생성은 프로세스 생성보다 더 적은 resource를 필요로 한다. 프로세스 내의 자원을 공유한다.- system 관점 thread : 메모리 관리, signal handling thread가 있다.
- Application 관점 thread :
main thread1개가 있다. 해당main thread는 다른 thread를 생성할 수 있다.
Defining and Starting a Thread
Thread instance를 생성하는 2가지 방법이 있다. 코드는 여기서볼 수 있다.
-
Threadclass를 상속받아서runmethod를 overriding 하는 방법.public class ThreadBasicThread extends Thread { public static void main(String[] args) throws InterruptedException { System.out.println("Main Thread Start"); ThreadBasicThread thread = new ThreadBasicThread(); thread.start(); thread.join(); System.out.println("Main Thread End"); } @Override public void run() { System.out.println("Thread Start"); // Logic... try { Thread.sleep(2000); // 그냥 2초 쉬는 행위가 끝 } catch (InterruptedException e) { } // ...logic System.out.println("Thread End"); } }Main Thread Start Thread Start Thread End Main Thread EndThread Start가 출력된 2초 후에Thread End부터 출력된다. 아래도 마찬가지의 결과가 나온다. -
Runnableinterface의runmethod를 구현하여 사용하는 방법.public class ThreadBasicRunnable implements Runnable { public static void main(String[] args) throws InterruptedException { System.out.println("Main Thread Start"); Thread thread = new Thread(new ThreadBasicRunnable()); // Thread class 생성자의 인자로 들어간다. thread.start(); // thread 실행 시작위한 method 호출 thread.join(); System.out.println("Main Thread End"); } @Override public void run() { System.out.println("Thread Start"); // Logic... try { Thread.sleep(2000); } catch (InterruptedException e) { } // ...logic System.out.println("Thread End"); } }
아니 비슷해보이는데 왜 굳이 2개로 구현할 수 있게 했을까…?
라는 의문이 가장 먼저 들었다. 그리고 난 운영체제에 대해 공부할 때 extends Thread만 있는 줄 알았기에 더 궁금했다.
먼저 Runnable interface를 한번 보도록 하자.
// Runnable.java
package java.lang;
@FunctionalInterface
public interface Runnable {
/**
* When an object implementing interface Runnable is used
* to create a thread, starting the thread causes the object's
* <code>run</code> method to be called in that separately executing
* thread.
* <p>
* The general contract of the method <code>run</code> is that it may
* take any action whatsoever.
*
* @see java.lang.Thread#run()
*/
public abstract void run();
}
그 다음에는 Thread class를 보도록 하자.
// Thread.java
public class Thread implements Runnable {
...
public Thread(Runnable target) {
this(null, target, "Thread-" + nextThreadNum(), 0);
}
...
@Override
public void run() {
if (target != null) {
target.run();
}
}
...
}
자세한 내용까지는 잘 모르겠지만 Thread class는 Runnable interface의 구현체라는 사실을 알 수 있었다. 둘로 thread를 생성했을 때 차이점은 ‘구현하느냐’ or ‘상속받느냐’의 차이로 구분할 수 있는데 여기서 Runnable을 일반적으로 쓰이는 이유가 나타난다.
Runnableobject, is more general, because theRunnableobject can subclass a class other thanThread.
Runnable을 구현하게 되면 Thread를 무조건 상속받을 필요가 없어지기에 다른 class를 상속받을 수 있게 된다. 따라서 일반적으로 쓰이는데, Thread는 간단한 프로그램을 만들 때 쓰기 쉽다는 장점을 가지고 있다 한다.
… easier to use in simple applications, but is limited by the fact that your task class must be a descendant of
Thread.
Pausing Execution with Sleep
Thread.sleep() method 특정 기간동안 현재 실행중인 thread를 중지하게 해준다. 이는 실행 중일 수 있는 다른 application or thread에게 processor의 시간을 사용할 수 있게 해주는 효율적인 방법이다. 그러나 운영체제에 의해 기본으로 제공되는 기능에 의해 제한되기 때문에 중지되는 시간이 정확하다는 보장이 없다.
However, these sleep times are not guaranteed to be precise, because they are limited by the facilities provided by the underlying OS.
InterruptedException: 다른 thread가sleep()상태인 현재 thread에 interrupt할 때 던지는 예외이다.
Interrupts
An interrupt is an indication to a thread that it should stop what it is doing and do something else.
thread가 interrupt를 받았을 때 어떻게 해야할지는 개발자의 몫이지만 thread를 종료시키는게 일반적이라고 한다.
It’s up to the programmer to decide exactly how a thread responds to an interrupt, but it is very common for the thread to terminate.
thread의 run() method에서 InterruptedException를 자주 던질 수 있는 method가 호출된다면, try-catch를 통해 exception을 처리한다. 제공된 예시 코드를 보도록 하자.
for (int i = 0; i < importantInfo.length; i++) {
// Pause for 4 seconds
try {
Thread.sleep(4000);
} catch (InterruptedException e) {
// We've been interrupted: no more messages.
return;
}
// Print a message
System.out.println(importantInfo[i]);
}
InterruptedException를 던지지 않는 method에 대해서는 아래와 같이 처리해준다고 한다.
for (int i = 0; i < inputs.length; i++) {
heavyCrunch(inputs[i]);
if (Thread.interrupted()) { // interrupt 발생하면 return true
// We've been interrupted: no more crunching.
return;
}
}
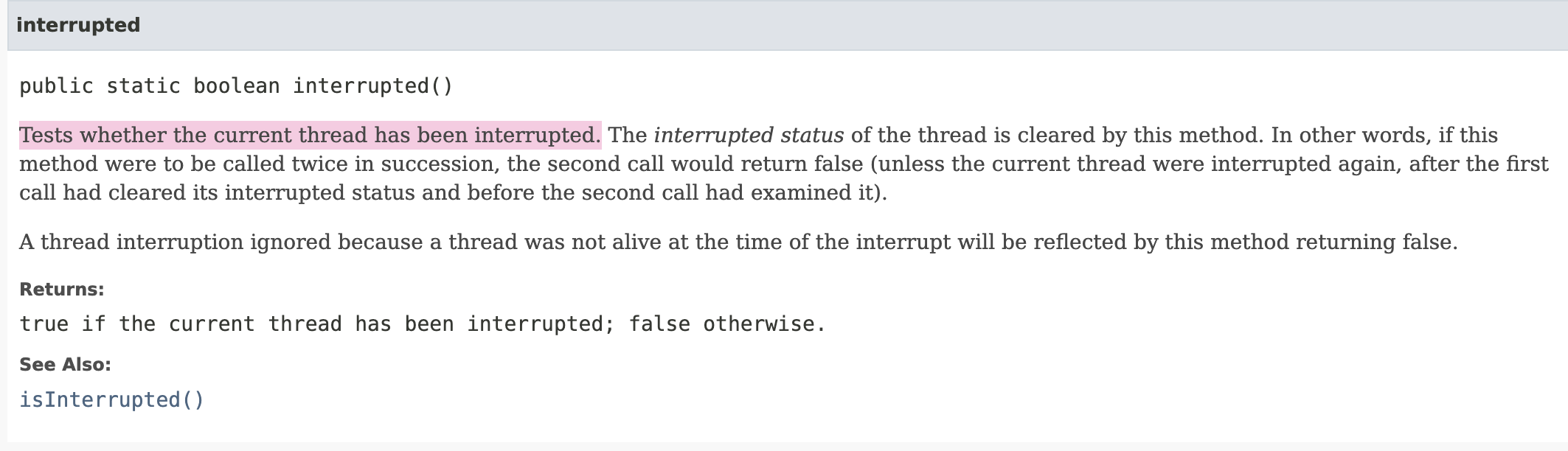
interrupted()method에 대한 설명을 보면 위와 같다. 따라서 예외를 안던지는 method에 대해 thread 내에서 주기적으로 확인을 해주는 작업을 거쳐야 한다.
Interrupt mechanism은 interrupt status라는 내부 flag로 실행된다. Thread.interrupt를 호출하게 되면, 해당 flag를 1로 만든다. thread가 Thread.interrupted() static method로 interrupt가 발생했는지 확인할 때 해당 flag가 0이 된다.
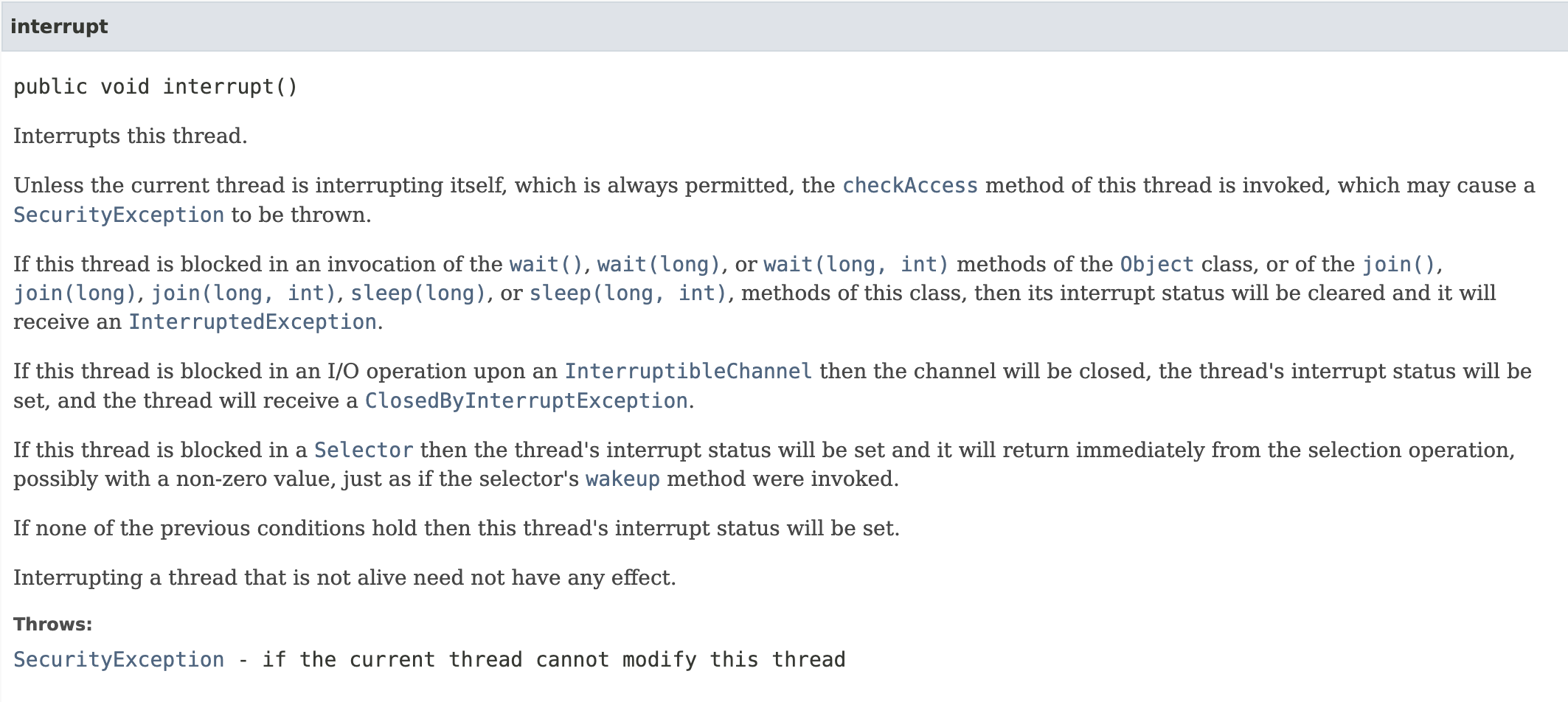
start() method
Thread 객체를 생성하면 start()라는 method로 해당 thread 객체를 시작상태로 만들 수 있다. 근데 그렇다면 왜 run을 굳이 한번 더 구현하는 것일까?
그 이유는 start()method를 호출해야 새로운 thread를 생성하고 run()method를 호출하기 때문이다. 다음 그림을 보도록 하자.
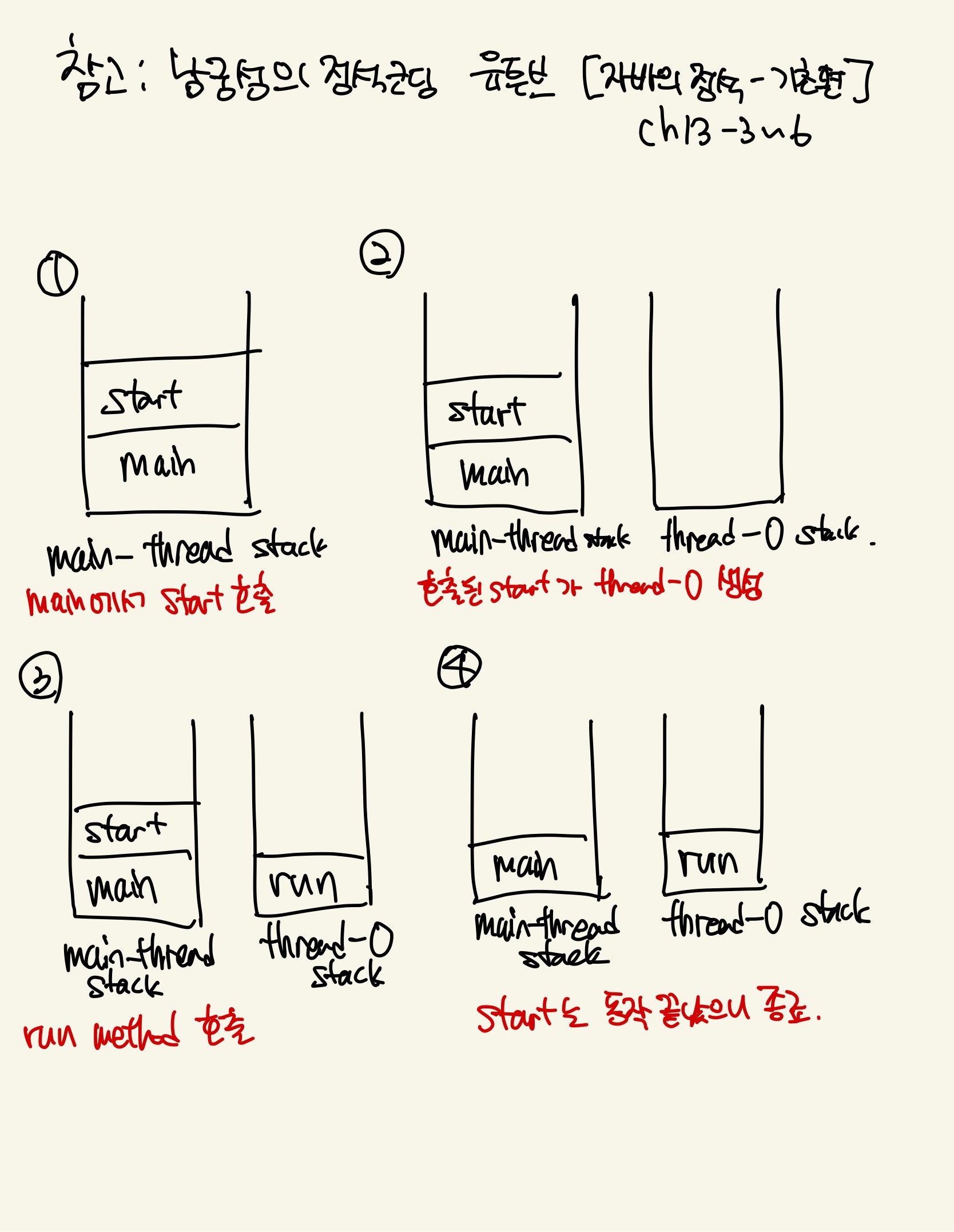
run()method를 바로 호출한다고 가정해보자. 그렇게되면, main stack의 main()위에 바로 run()method가 쌓인다. 그렇게 되면 Multi-Thread로 실행시키는게 아닌, main thread하나로 실행시키는 것과 마찬가지이다.
진짜 새로운 Thread만들까…?
// Thread.java
...
public synchronized void start() {
...
boolean started = false;
try {
start0();
started = true;
} finally {
try {
if (!started) {
group.threadStartFailed(this);
}
} catch (Throwable ignore) {
/* do nothing. If start0 threw a Throwable then
it will be passed up the call stack */
}
}
}
private native void start0();
...
Thread.java의 start()method에 관한 내부 코드이다. start0이라는 native method를 호출하는 것을 볼 수 있는데 여기서 새로운 thread를 생성해주는 것이다. 그리고 start()가 호출되는 순간 해당 thread가 시작되는 것이 아니다. OS스케쥴러가 실행순서를 결정하기 때문에 start()는 ‘실행가능한 상태가 되게 해주는’ 역할을 한다고 볼 수 있다.
joins() method
The
joinmethod allows one thread to wait for the completion of another.
현재 실행되고 있는 A thread를 B thread가 끝날 때까지 기다리게 하고 싶다면,
B.joins();
를 써주면 된다. A는 B가 끝날 때까지 기다리게 된다. joins()method를 overload한 method를 만든다면, 개발자가 직접 기다리는 시간을 지정할 수 있게 된다.
Synchronization
Threads는 field와 참조하는 object reference field 에 대한 접근을 공유하여 통신한다. 이러한 통신은 효율적이지만, 2가지 문제를 만들 수 있다.
-
thread interference error : 서로 다른 thread에서 동일한 데이터에 대해 접근하는 두 작업이 interleaving될 때 발생하는 에러. 여러개의 thread가 공유자원에 접근할 때 동일한
context-switching이critical-section의 어디에서 일어날지 알 수가 없기 때문에 발생한다. 아래의 코드를 보도록 하자. (코드 예제 원본)import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.TimeUnit; public class ThreadInterferenceTest { public static void main(String[] args) throws InterruptedException { ExecutorService executorService = Executors.newFixedThreadPool(10); // Thread 10개 생성 Counter counter = new Counter(); for (int i = 0; i < 1000; i++) { executorService.submit(() -> counter.increment()); // counter.increment() 라는 행위를 multi-threading 으로 처리하겠다는 코드 } executorService.shutdown(); executorService.awaitTermination(60, TimeUnit.SECONDS); System.out.println("counted value = " + counter.getValue()); /** * 우리의 의도는 1000번의 increment() method 호출의 결과가 value = 1000 의 결과를 가져올 것이라 생각. * 그러나 그렇게 되지 않고 995, 1000, 996, 999, 999... 등 1000이 아닌 수들이 나오는 것을 발견. * → 일관되지 못한 결과를 보여주고 있다. * * 왜 그런지에 대해 알아보도록 해보자. (참고 : https://www.callicoder.com/java-concurrency-issues-and-thread-synchronization/) * increment() method 의 동작에 대해 보면, * 1. count instance 의 value 변수 값을 가져온다. * 2. 가져온 value 변수에 1 추가. * 3. 추가된 value 변수를 저장. * 의 과정을 거치게 된다. 근데 이걸 여러개의 thread 가 동시에 하게 된다면...? 을 생각해보자. * * 당장 A, B 2개의 thread 만 간단하게 생각해봐도, * 1. A Thread 가 count instance 의 value 변수 값을 가져온다. (value = 0) * 2. B Thread 가 count instance 의 value 변수 값을 가져온다. (value = 0) * 3. A Thread 가 가져온 변수 값에 1 추가. (value = 1) * 4. B Thread 가 가져온 변수 값에 1 추가. (value = 1) * 5. A, B 둘 다 가져온 값 저장.=> 둘 다 1을 저장하게 된다... * * 원래 예상대로라면, A Thread 가 value++을 하고 난 뒤에 B Thread 가 value++을 해서 * value=2 가 될 것이라 생각했지만, Thread 로 실행된 두 연산이 서로 interleaving 됐기 때문에 * A Thread 가 한 일이 없던 일로 되어 버린 것이다. */ } static class Counter { int value = 0; public void increment() { value++; } public int getValue() { return value; } } }주석으로 설명한 A, B Thread 예시는 하나의 가능성을 얘기한 것이다. 중요한 것은 ‘동시에 공유자원에 접근’할 때 read, write 동작이 겹치면서 실행됐기에 해당 오류가 발생하여 결과 값을 예측할 수 없다는 것이다. 이러한 현상을
Race condition이라고 부른다. 공유자원에 접근하는 코드의 영역을critical-section이라고 부른다.synchronization로 공유자원에 접근하여 해결할 수 있다. -
memory consistency error : multi-threading에서 한 thread에 의해 변경된 내용이 다른 thread에 표시되지 않을 수 있고, 따라서 모든 thread에게 공유되는 자원이 각각의 thread들에게 다 다르게 보일 수 있는 것을 말한다.
Memory-consistency에 대한 실험코드를 여기에올려놨다. 해당 코드는 여기를참고했다.
공유하는 자원에 대한
happens-before관계를 이해하면 해결할 수 있다. 쉽게 말하면, 공유 자원이 ‘변경됐다는 사실’을 알려준 뒤 읽게하는 것이다.This relationship is simply a guarantee that memory writes by one specific statement are visible to another specific statement.
그
happens-before의 방법 중 하나가synchronization이다. -
둘의 차이점?
Thread-interference는 하나의 공유자원에 접근하려는 각 thread들의 동작이 겹쳐서 생기는 간섭에 대해 문제가 생기는 것이다.Memory-Consistency는 그렇게 동작이 겹쳤을 때 공유되는 자원이 일관성을 유지하지 못한다는 것이다. 아래 그림은 memory-consistency 에 관한 그림이다.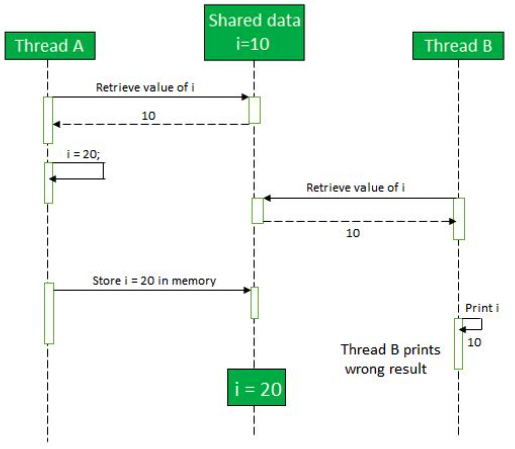
위 2개의 오류를 해결하기 위해 synchronization을 쓴다고 했는데 이는 또 thread contention문제를 발생시킬 수 있다.
Synchronized Methods
Java에서는 synchronization idiom으로 synchronized methods 와 synchronized statements를 제공한다. 먼저 synchronized methods 에 대해 알아보도록 하자.
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class SynchronizationMethod {
public static void main(String[] args) throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(10); // Thread 10개 생성
Counter counter = new Counter();
for (int i = 0; i < 1000; i++) {
executorService.submit(() -> counter.increment()); // counter.increment() 라는 행위를 multi-threading 으로 처리하겠다는 코드
}
executorService.shutdown();
executorService.awaitTermination(60, TimeUnit.SECONDS);
System.out.println("counted value = " + counter.getValue());
/**
* Counter class 의 increment() method 는 thread 가 공통으로 접근하는 critical-section 이다.
* 따라서 해당 method 에 synchronized keyword 를 추가하여 선언해주면,
* 해당 method 에는 한번에 1개의 thread 만 접근이 가능해진다. => interleaving 제거
*/
}
static class Counter {
int value = 0;
public synchronized void increment() {
value++;
}
public int getValue() {
return value;
}
}
}
- 동일 객체에 대해 synchronized method의 호출들이 interleave 될 수 없게 된다. 한 thread가 객체의 synchronized method를 실행할 때, 동일한 객체에 대해 synchronized method를 호출하는 다른 모든 thread들은 실행을 일시 중단한다.
- 이어서 발생하는 동일 객체에 대한 synchronized method의 호출들은 자동적으로
happens-before관계를 수립하게 된다. 따라서 모든 thread들에게 객체의 변경사항들을 알 수 있게 해준다.
그리고 constructor에 sychronized 키워드를 붙이는건 의미가 없다고 한다. Syntax error 가 발생한다고도 한다.
→ 객체가 생성될 때는 오직 ‘해당 객체를 생성하는 thread만 생성자에 접근’할 수 있기 때문에 있어도 의미가 없다.
Synchronized methods는 thread interference와 memory consistency errors를 예방할 수 있는 좋은 전략이다. 효과적이지만, liveness라는 문제를 발생시킬 수 있다. 이는 향후 포스팅에서 보도록 하자.
Rerference
Daemon Thread vs Normal Thread - medium
Java JDK 8 Concurrency - Java docs
Multi-Programming/Processing/Threading
Thread Interference error, Memory Consistency error
Thread Interference error, Memory Consistency error - example code