on
JPA 1
JPA 공부 시작!
Ssafy study 자료 정리 + JPA 공부한 내용을 정리하기 위해 만든 tag.
JPA!!
JPA에 대해 포스팅 하게 됐다. JPA는 무엇일까?
JPA :
Java Persistence API는 Java 객체와 RDB 간의 데이터 접근, 지속 및 관리를 위한 Java specification. Java 진영의 ORM 기술 표준이다. - 출처
그렇다고 한다. 그렇다면 ORM은 뭘까?
ORM(Object-Relational Mapping) : DB와 OOP 언어 간의 호환되지 않는 데이터를 변환하는 프로그래밍 기법. - 출처
결국 요약하자면, 우리는 Java로 Application 개발을 할 때 회원관리를 하거나… 또는 그런 비슷한 것을 하게될 수 있다. 이럴 때 해당 데이터를 ‘저장’ 해야할 필요가 있는데, 이 저장을 Database라는 곳에 한다. DB는 SQL이라는 언어를 사용하고, Application은 Java라는 언어를 사용하는 차이점으로 인해 ORM으로 OOP 언어의 객체라는 개념을 DB의 table과 매핑시켜주는 것이다. 따라서 ORM이라는 기술을 쓰게되는 것.
한번 더 정리하자면,
- ORM이란… - 출처:JPA 기본편1(인프런 김영한 강사님)
- 객체는 객체대로 설계
- DB는 DB대로 설계
- ORM framework가 중간에서 매핑!
자 그렇게 JPA가 Java진영의 ORM 기술 표준이라는 것을 알았고, 우리가 왜 ORM기술을 써야하는지도 알았다. 그래서 JPA는 무엇일까..? 더 자세히 설명해보도록 하자.
JPA : interface의 모음. 특정 기능을 하는 library가 아니다. 따라서 구현이 없다.
…? 아니 그러면 JPA를 왜 쓰는거고, 어떻게 쓰는 것일까?
JPA를 왜 쓸까?
왜 JPA를 사용할까? ORM기술을 사용해야 DB와 객체를 매핑할 수 있음을 알기에 당연히 사용해야한다고 생각한다. 하지만 왜 하필 JPA일까? 다른 ORM기술은 없었을까? 예전에는 DB에 접근하기 위해 어떤 기술이 있었을까? 한번 자세히 알아보도록 하자.
Web 통신 기술의 발전에 따라 DB의 중요성이 더 높아졌고, 각 언어와 DB를 연결해주는 DB connection 기술이 등장했다. Java진영에서는 JDBC API가 있다. 이러한 기술도 그 당시에는 획기적일 수 있겠지만… JDBC를 지금 한번이라도 써봤다면 불편해서 짜증이 날 수도 있을 정도로 개발자가 신경써줘야 할게 많다.. 여기를 보면 일일히 개발자가 String type으로 sql query를 작성하여 DB 연결 얻고… 파라미터 바인딩 해주고… 결과값 받아주고.. 해야한다. 만약 여기서 수정사항이 발생한다? 바로 모든 table에 대한 query를 수정해줘야 한다…
심지어 실수하기도 쉬웠고, 어느순간 이런 SQL에 신경쓰다보니 정작 중요한 application개발에 신경을 덜 쓰게 되는 것이었다. 따라서
우리 SQL과 Application code를 분리시키자!
라며 등장한게 MyBatis라는 SQL Mapper이다. JDBC API, ORM얘기하다가 갑자기 SQL Mapper? 라는 생각이 들 수 있다. 일단 보길 바란다.
MyBatis: Java Persistence Framework 중 하나로 XML이나 annotation을 사용하여 OOP의 객체와 SQL을 매핑하여 연결하는 것
SQL Query는 xml에서 관리! Application code는 java에서 관리! 하여 분리를 시키자! 라는데 의미가 있는 것이었다. 왜냐하면 기존 자바에서는
public Member save(Member member) {
// 직접 SQL Query 를 작성해줘야 한다.
String sql = "insert into member(name) values(?)";
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
try {
conn = getConnection(); // connection 가져오기
pstmt = conn.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS); // DB 에 Key(id) 자동으로 설정된다.
pstmt.setString(1, member.getName());
pstmt.executeUpdate(); // DB 에 실제 query 날라간다
rs = pstmt.getGeneratedKeys();
if (rs.next()) {
member.setId(rs.getLong(1));
} else {
throw new SQLException("id 조회 실패");
}
return member;
} catch (Exception e) {
throw new IllegalStateException(e);
} finally {
close(conn, pstmt, rs);
}
}
위와같이 String에 sql을 작성해서 query를 날리는 방식으로 사용했기 때문이다. 따라서 이러한 SQL을 XML에서 관리하자는 것이었다.
따라서 아래와 같이 xml파일에서 query를 작성해줬다.
<select id="selectPerson" parameterType="int" resultType="hashmap">
SELECT * FROM PERSON WHERE ID = #{id}
</select>
그러면 된거 아닌가?
저렇게 끝나면 JPA가 등장하지 않았을 것이다. MyBatis와 같은 SQL Mapper는 결국
SQL 중심적인 설계가 된다는 것.
우리는 객체지향 언어를 사용하여 객체지향 설계를 하려고 하는데 자꾸 SQL을 만지고.. SQL에 id, type 등등을 신경써주고 해야한다. 결국,
물리적 분리인 ‘코드의 분리(SQL과 JDBC API 분리)’는 성공했을지라도, 논리적으로는 강한 의존성을 가지고 있는 것.
이러한 점이 SQL에 의존적인 개발이 되는 원인이 됐다.
아니 분리를 했는데 뭐가 문제? SQL에 왜 의존적이게 되는건가?
DB는 SQL을 사용하고, OOP은 객체지향 언어를 사용하게 된다. 여기서 발생하는 paradigm의 불일치가 바로 SQL에 의존적이게 만드는 것이다. 사실 paradigm이 다르기에 우리는 객체를 SQL으로 mapping하는 방법에 대해 고민했고, 그 결과가 SQL Mapper인 것이었다.
다시 조금 원초적인 질문을 하겠다.
‘왜 SQL로 바꿔야 하나?’
좀 웃긴 질문이긴 하다. 당연하게도 DB에 저장하기 위해서이다.
왜 DB에 저장해야 하는가?
인터넷이 보급되고 급속도로 성장하면서 정보를 그저 휘발성 메모리에 저장할 수 없었기 때문이다. 우리는 Persistence하게 데이터를 저장하고 싶었던 것이다. (Persistence에 대해 아래서 설명할 것이다)
그래서 DB에 접근하기 위해서 객체지향언어와 연결점을 어떻게든 만들려고 하는데 다음과 같은 paradigm의 불일치 문제로 인해 SQL중심의 개발이 됐던 것이다. 먼제 객체와 DB의 특징에 대해 보도록 하자.
- 객체와 DB의 차이점
- 객체 : 속성과 method를 묶어서 캡슐화, 정보은닉, 추상화 등등을 하여 쓰인다
- DB : 데이터를 잘 정리하여 보관하는게 목적
일단 목적이 살짝 다르다. 객체는 애초에 저장을 위한 목적으로 생긴 개념이 아니기 때문에 paradigm불일치가 발생했던 것이다.
-
paradigm 불일치
-
상속 : 일단 DB에는 상속이라는 개념이 없다. 그러나 객체에는 존재한다. 아래와 같은 상황을 가정하자.
class Item { Long id; String name; } class Book extends Item { String author; String isbn; }이 있다고 하자. 만약 어떤 collection에 Book객체를 만들어서 저장한다고 하면,
collections.save(book);이라고 하면 될 것이다. 그러나 DB에서는 그렇지 않다.
DB에서는
Item과Book이라는 2개의 table에 각각 query를 날려줘서 DB에 저장할 수 있다.INSERT INTO ITEM .... INSERT INTO BOOK ... -
연관관계
- 객체 : reference를 통해 다른 객체에 접근할 수 있다.
- RDB : table은 FK를 사용하여
JOIN ON M.TEAM_ID = T.TEAM_ID와 같은 join query로 접근할 수 있다.
class Member { Long id; Team team; String username; } class Team { Long id; String name; }객체는 위와 같이
member.getTeam()으로Team객체에 접근이 가능하다. 그러나 DB의 경우에는team_id라는 FK로 접근이 가능하다….뭔가 이상하지 않는가..? 위 객체에서
team_id가 Member라는 클래스에 존재하는가…? 그렇지 않다. 지금 위에 작성된 java code는 객체지향 스럽게 설계됐기 때문에 team이라는 field를 그냥 만든 것이다. 객체는 참조로 연결되어 있으니깐 말이다.그렇다면 어떡하는가? 그렇다. 우리는 DB에 저장할 필요가 있기에 ‘DB에 맞춰서 Query가 날라가게끔’ 객체를 바꿔줘야할 필요가 생긴다. 아래 코드를 보도록 하자.
class Member { Long id; // PK member_id // Team team; Long teamId; // FK team_id String username; }자, 이제 위와 같이 바꿔줬기에 SQL을 다음과 같이 만들어서 query를 보낼 수 있다.
INSERT INTO MEMBER(member_id, team_id, username) VALUES (....)느껴지는가? 우리는 우리도 모르게 ‘SQL에 맞춰서 코딩을 했다는 것’이…
Q) ??? : 그냥
member.getTeam().getId()하면 안되는건가요?해보도록 하겠다. 이번에는 SQL에서 벗어나보도록 하자.
class Member { Long id; Team team; // team_id = member.getTeam().getId() 로 얻어서 SQL Query에 넣어준다. String username; } class Team { Long id; String name; }INSERT INTO MEMBER(member_id, team_id, username) VALUES (....)끝…? 뭐야 이렇게 되면 그냥 객체지향스럽게 하면 되는거 아닌가? 라는 생각이 들 수 있다. 지금 위 코드는 ‘조회’시 문제가 생긴다.
# excuteSQL SELECT M.*, T.* FROM MEMBER M JOIN TEAM T ON M.TEAM_ID = T.TEAM_Idpublic Member findMember(Long memberId) { result = excuteSQL(sql); // SQL 실행. Team과 Member에 대한 정보를 가져온다. Member member = makeMember(result); // 위 결과에서 Member에 해당하는 속성을 가져와서 member 객체에 모두 저장. Team team = makeTeam(result); // 위 결과에서 Team에 해당하는 속성을 가져와서 team에 모두 저장. member.setTeam(team); // member의 team 속성에 team정보 저장. return member; }하고싶었던 말은 ‘SQL날려서 member, team에 대한 정보 각각 정리해서 넣어준 다음에, 다시 member에 team에 관한 정보를 넣어줘야 한다는 번거로움’이다. 이를 만약 Java collection에 넣는다고 생각하면,
list.add(member); // member 객체 저장. Member findMember = list.get(memberId); // list에서 id에 해당하는 member가져온다. Team team = findMember.getTeam();엄청 간단해진다! 하지만 위와 같이 하면 생기는 문제점은 또 DB에 넣으려고 할 때다… 중간에서 개발자가 하나하나 다 매핑을 해줘야 하기 때문에 생산성이 오히려 떨어진다고 한다.
-
객체 그래프 탐색 문제
객체는 참조로 자유롭게 탐색될 수 있어야 한다. ex)
getTeam(),getMember(),getOrder()등등…그러나 SQL이 만약에 처음부터
Team에 대한 Join없이 쿼리를 날렸다면…? 우리는 받은 Member객체로부터 Team에 대한 정보는 기대할 수가 없는 것이다. → Entity에 대한 신뢰문제가 발생따라서 상황에 따라 동일한 조회 method를 만들어야 할 수 있다…
public Member getMember(); // 진짜 Member table만 조회해서 가져오기 public Member getMemberWithTeam(); // Member table과 Team table을 JOIN해서 가져오기 public Member getMemberWithTeamWithOrder(); ... -
비교하기
조회하여
Id=1에 해당하는Member객체를 하나 가져왔다고 해보자. 또 같은 Id로Member객체를 가져왔다고 해보자. 과연 이 둘을==비교했을 때 같을까? 정답은 아니다. 같지 않다. 조회를 수행할 때 마다 새로운 객체를 생성하여Member를 만들기 때문이다.만약 Java collection에서 같은 Id의 객체를 꺼내와서 비교했다면 같다고 될 것이다.
-
계속 Java collection에서는…, Java collection이라면… 계속 이렇게 말했는데 결국 하고 싶은 말은 이거였다.
객체를 Java Collection에 저장 하듯이 DB에 저장할 수는 없을까?
라는 고민의 결과가 JPA라는 것이다. JDBC API, SQL Mapper를 거쳐 JPA가 등장하게 된 배경에 대해서 알아봤다.
근데 ORM, JDBC API, Spring JDBC API, Spring Data JDBC, JPA, Spring Data JPA, Hibernate…이게 다 뭔가요?
- 인터넷 성장. DB connection 기술 필요 →
JDBC API등장. 해당 DB에 맞는 JDBC Driver가 구현체로 있다면 사용가능. - 매우 불편함. 이유는 위에서 알아봄. SQL Mapper
MyBatis와 Spring JDBC interface등장(JdbcTemplate class로 JDBC API를 한번 더 추상화한 것). - 그러나 SQL중심적인 개발을 못 피함. 따라서 ORM 등장. 객체는 객체대로! DB는 DB대로! 설계하는게 목적. → JPA등장.
- 예전에 EJB이 ORM으로 있었지만, 성능이 안좋고 쓰기 불편했음.
Gavin King이라는 분이Hibernate라는 것을 오픈소스로 만듦. - Java진영에서
Gavin King이라는 분을 모셔다가JPA만들게 함. - JPA는 interface들의 모임. 따라서 구현체가 필요함. 가장 유명한 구현체가
Hibernate인 것. - JPA에서
EntityManager로 Java collection처럼 DB조작 가능하게 됨. 그러나 이 또한 중복이 많다고 생각되어 나타난 모듈이 바로Spring Data JPA. repository를 interface로 만들고, 명세에 맞게 method이름을 정해주면 자동으로 repository가 구현됨. - 다른거 됐고 간단하게 쓰자! 하면서 등장한게 Spring Data JDBC
JPA가 뭔데…
자, 지금까지 ORM을 써야하고, 그 표준인 JPA를 왜 써야하는지에 대한 이유와 배경에 대해 알아봤다. 이제 JPA가 무엇인지에 대해 알아볼 차례이다. JPA는 Java Persistence API이다. 대단한 것.. 맞지만 뭐 별 다른게 아니라 인터페이스들이 모여 있는 것이다. 아래 구조를 보도록 하자.
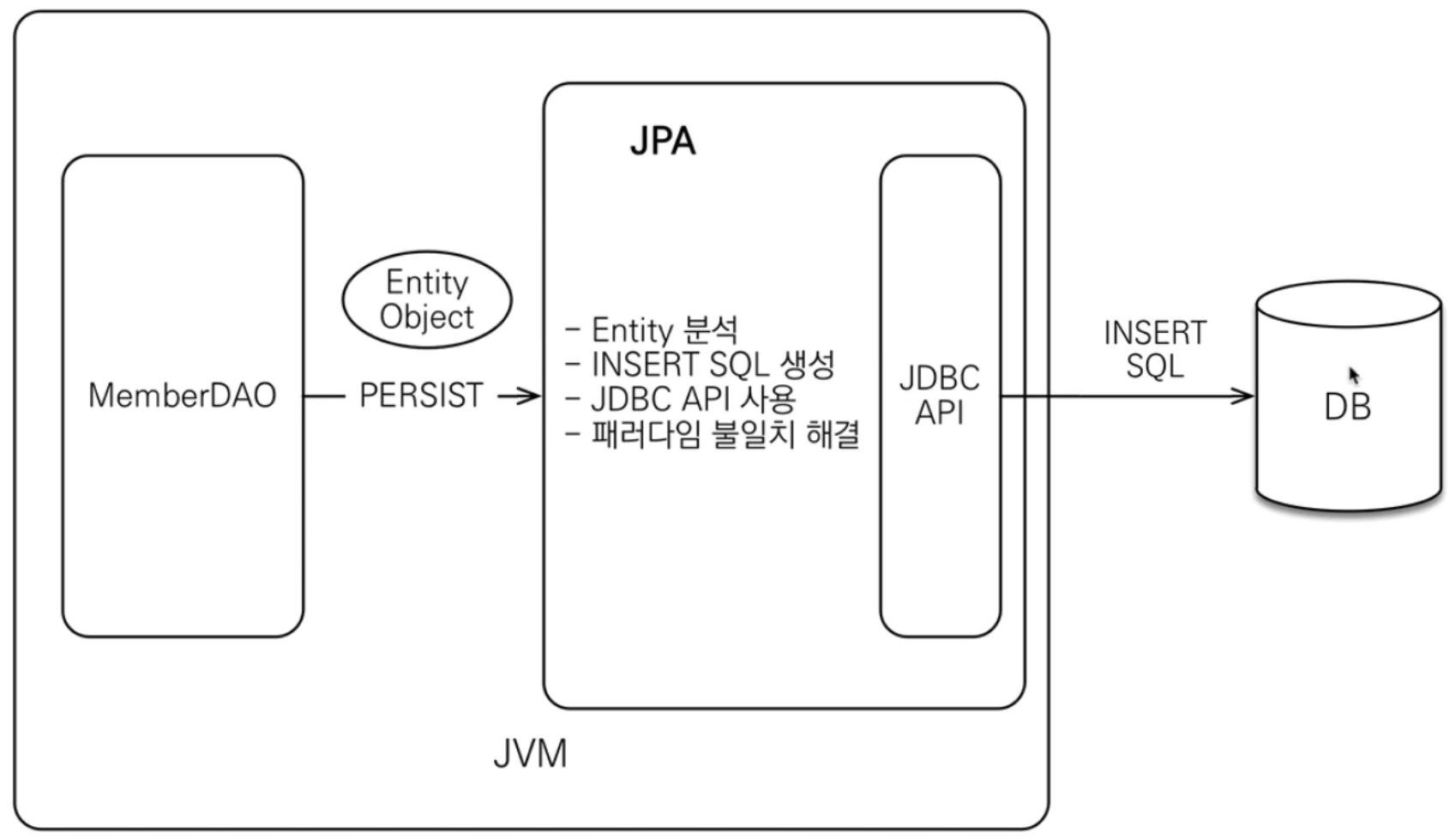
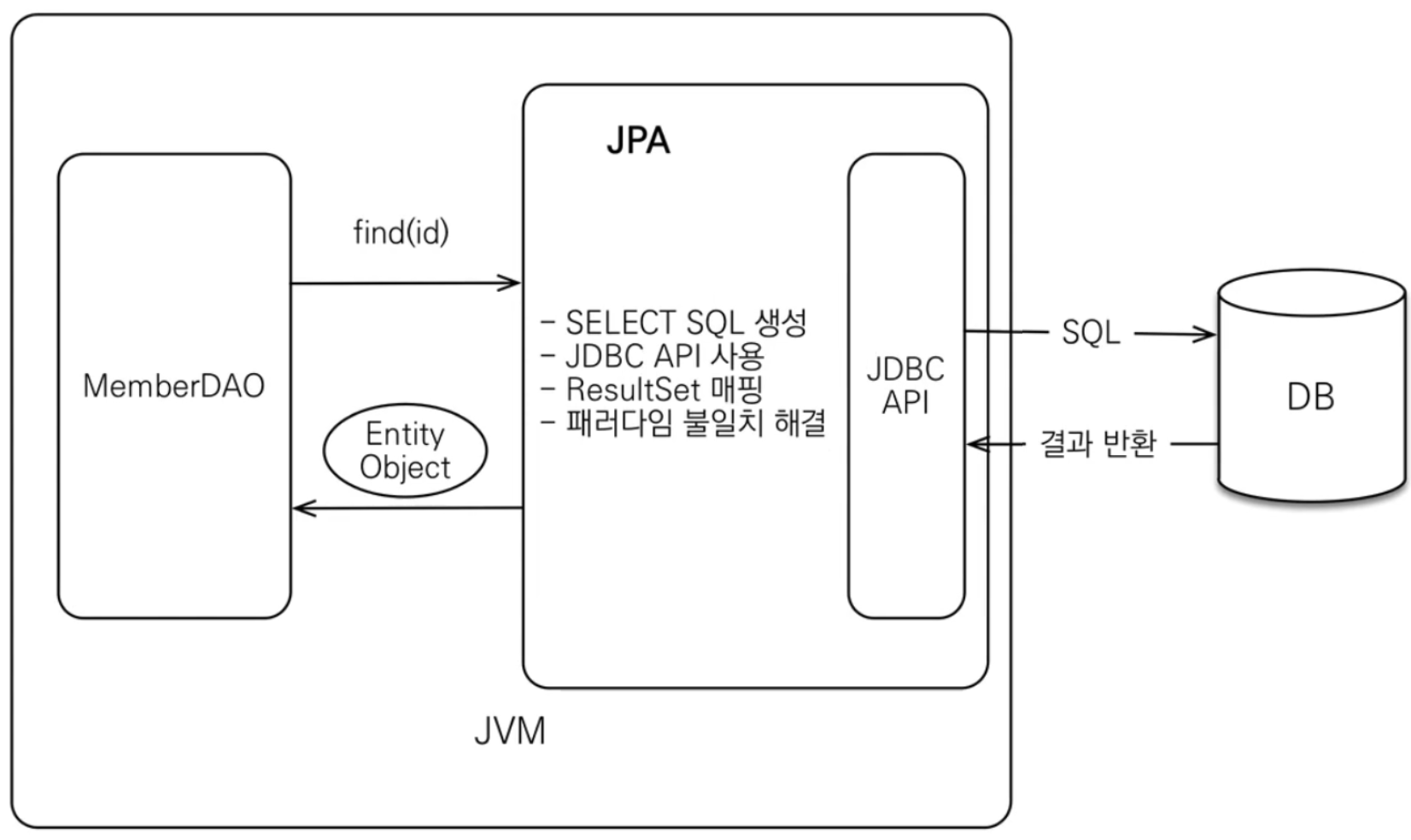
사진 출처 : 인프런 김영한 강사님 - JPA 기본편1
위 사진은 각각 JPA로 DB에 저장, 조회 할 때를 나타낸 것이다. 아까 봤던 JDBC API도 볼 수 있다. 따라서 JPA는 ‘JDBC API와 application사이에서 동작’함을 알 수 있다.
이러한 JPA에는 중요한 개념이 있다. PersistenceContext이다. 우리말로 직역하자면 ‘영속성 컨텍스트’라고 부를 수 있다.
Persistence Context : Entity를 영구 저장하는 환경.
JPA에서는 EntityManager라는 class가 객체를 persist(객체)해주면, 해당 객체를 영속성 컨텍스트에 저장하여 JPA가 관리하겠다는 뜻을 나타내는 것이다.
Persistence
영속성 컨텍스트에 대해 말하기 전에 처음부터 계속 말해왔던 Persistence에 대해 먼저 알아보도록 하자.
Persistence: 데이터를 생성한 프로그램이 종료되더라도 사라지지 않는 data의 특성
?? DB에 저장하는데 왜 데이터가 사라질 걱정을 하는거지? 라는 생각이 들 수 있다. 예전에는 DB가 아닌 휘발성 메모리와(RAM) 같은 곳에 데이터를 저장했고, 당연하게도 이는 컴퓨터가 종료됨에 따라서 모든 데이터도 같이 사라졌다. 당연하게도 데이터를 영구히 저장하고 싶어했고, 따라서 등장한게 Persistence라는 개념인 것이다.
JPA에서는 Persistence Context라는 곳에 데이터를 영구 저장하기 때문에 해당 개념을 잠깐 소개했다.
Persistence Context
Persistence Context : Entity를 영구 저장하는 환경.
-
논리적인 개념.
-
EntityManager를 통해 접근할 수 있다. -
장점
-
1차캐시
객체를 persist하여 영속성 컨텍스트에 저장하면,
1차캐시에 저장이 일단 된다.Member member = new Member("KJJ", 26); em.persist(member); // member 객체는 id=1 부여받는다고 하자.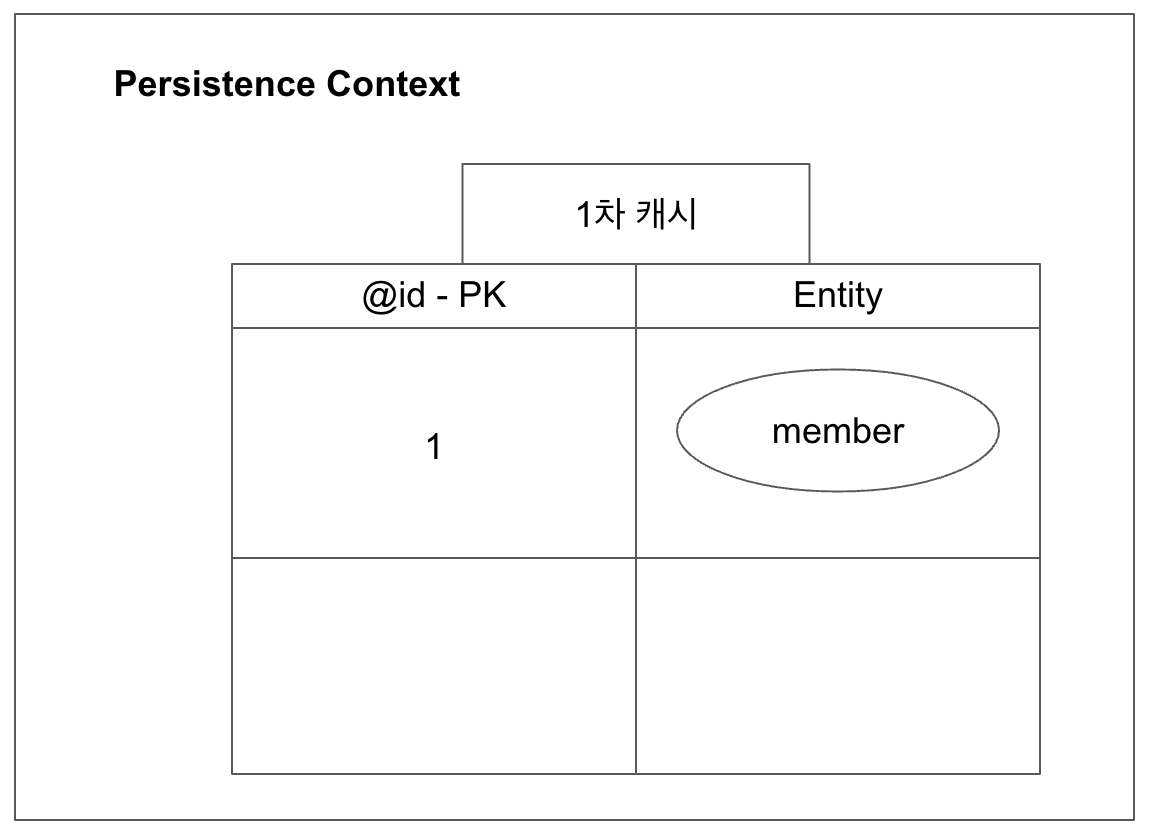
위 코드를 실행하면, 위 그림과 같은 상황이 된다. 이와 같이 쓰면 장점이, ‘조회’할 때 나타난다.
‘조회’할 때 1차캐시를 먼저 확인 후 없다면 DB를 탐색하게 된다. 따라서 DB의 불필요한 접근을 막아서 성능을 향상시킬 수 있는 것이다.
1차캐시에 ‘조회’하려는 정보가 없다면 DB에서 찾은 뒤, 1차 캐시에 저장한 다음 해당 객체를 반환해준다. 이후에 다시 해당 객체를 조회하려고 하면, 이번에는 당연하게도 1차캐시에서 찾기 때문에 더 빠른 조회가 가능하다!!
→ 사실 그렇게 큰 도움은 안된다고 한다.
EntityManager는 DB transaction단위로 생성되고, transaction은 끝날 때 종료된다. 따라서 고객의 요청이 들어오면 transaction이 생성되고, 요청을 다 수행하면 끝나게 되어Persistence Context를 지운다는 것이다. -
동일성 보장.
아까 위에서 SQL Mapper, JDBC API는 같은 id의 객체에 query를 날려도, 다른 객체를 각각 생성하기 때문에 2개의 객체 비교를 수행 시 다르다고 나온다. 그러나 JPA에서
find기능을 수행 시 같은 PK에 대해서는 같은 객체라고 동일성을 보장해준다. (같은 transaction 안에서만) -
transactional write-behind : 쓰기지연
보통
em.persist(객체)할 때 DB에 해당 객체를 저장하는 것이 아니다.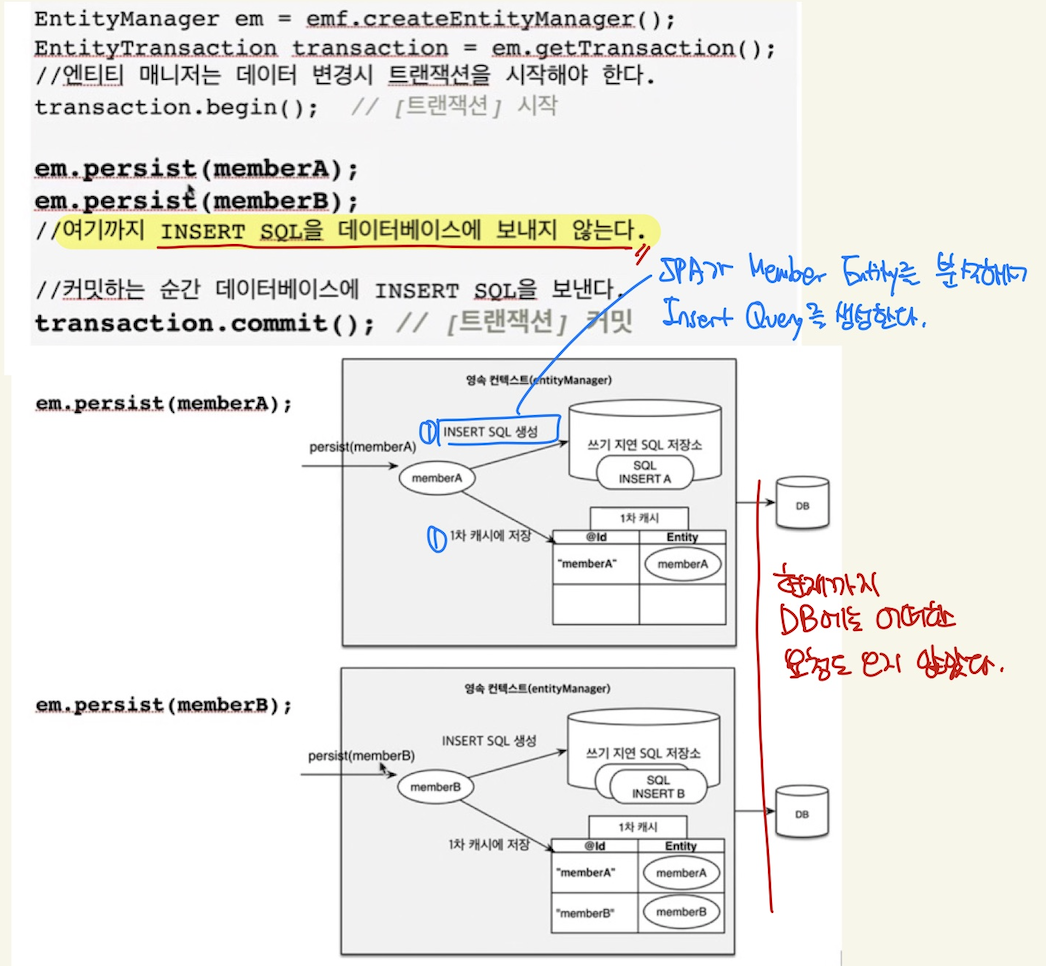
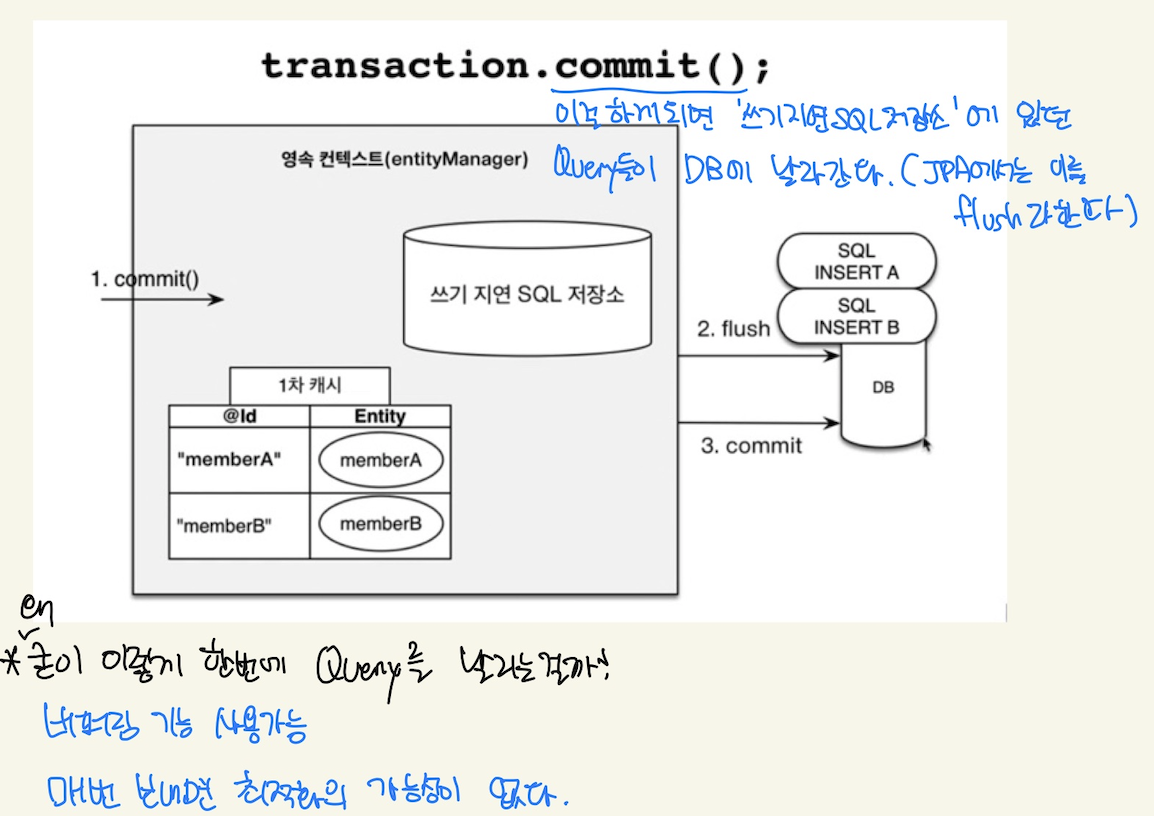
사진 출처 : 인프런 김영한 강사님 - JPA 기본편1
이렇게 매번 Query를 만들어서 DB에 보내는 것이 아니라, transaction commit 시 한번에 query를 보내게 되는 것이다…
여기서 드는 의문. Commit() 과 flush()는 뭐가 다른 것인가? 위 그림을 보면 마지막에
flush를 하고commit을 하는 것을 볼 수 있다. 도대체 뭐가 다른지 궁금해서 한번 찾아봤다.- flush : transaction 중 일련의 변경사항(과정)들을 DB에 실제로 반영하는 것. rollback이 가능하다.
- commit : transaction을 확정하고 끝났음을 표시. DB에 transaction의 모든 변경사항을 저장. rollback불가능.
정도로 이해하면 될 것 같다.
-
Dirty checking
JPA는 하나의 transaction 안에서 조회로 가져온 객체를 1차캐시에 저장함을 우린 위에서 알게됐다. 만약 우리가 그 객체를 수정하게 된다면? JPA에서는 1차 캐시와 우리가 수정한 객체를 비교하여 ‘변경이 발생했다면’ 해당 객체에 대한 Update query를 만들어서 쓰기 지연 저장소에 저장하게 된다. 그리고 나중에 flush-commit이 발생하면 DB에 해당 수정사항이 반영되는 것.
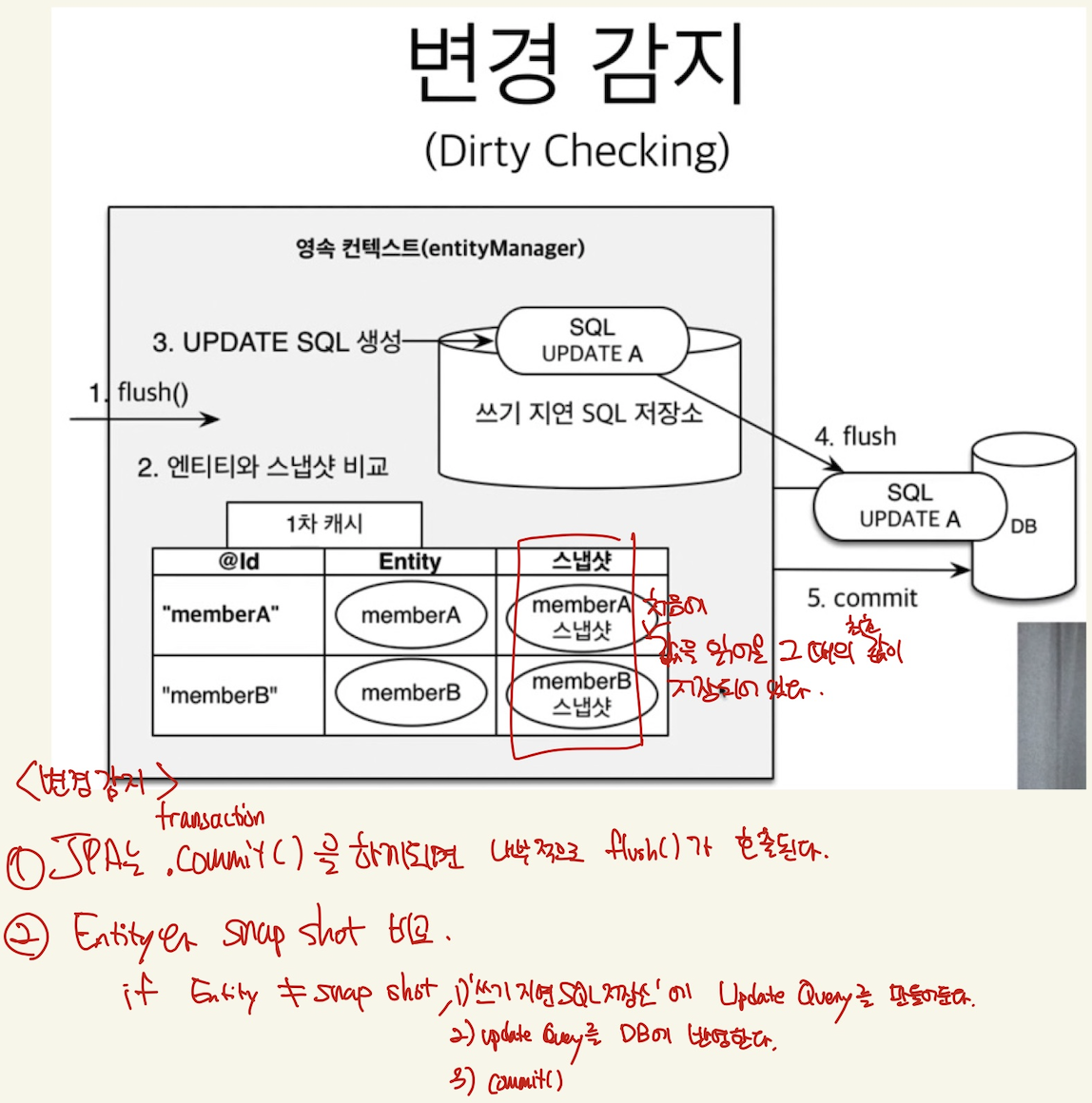
Snap shot에 처음에 읽어온 그 때의 값이 저장되어 있다. 따라서 해당 값과 다르면 Update Query 생성.
-
LAZY Loading : 다음 포스팅에서 자세히 다루도록 하겠다.
-
Entity Life Cycle
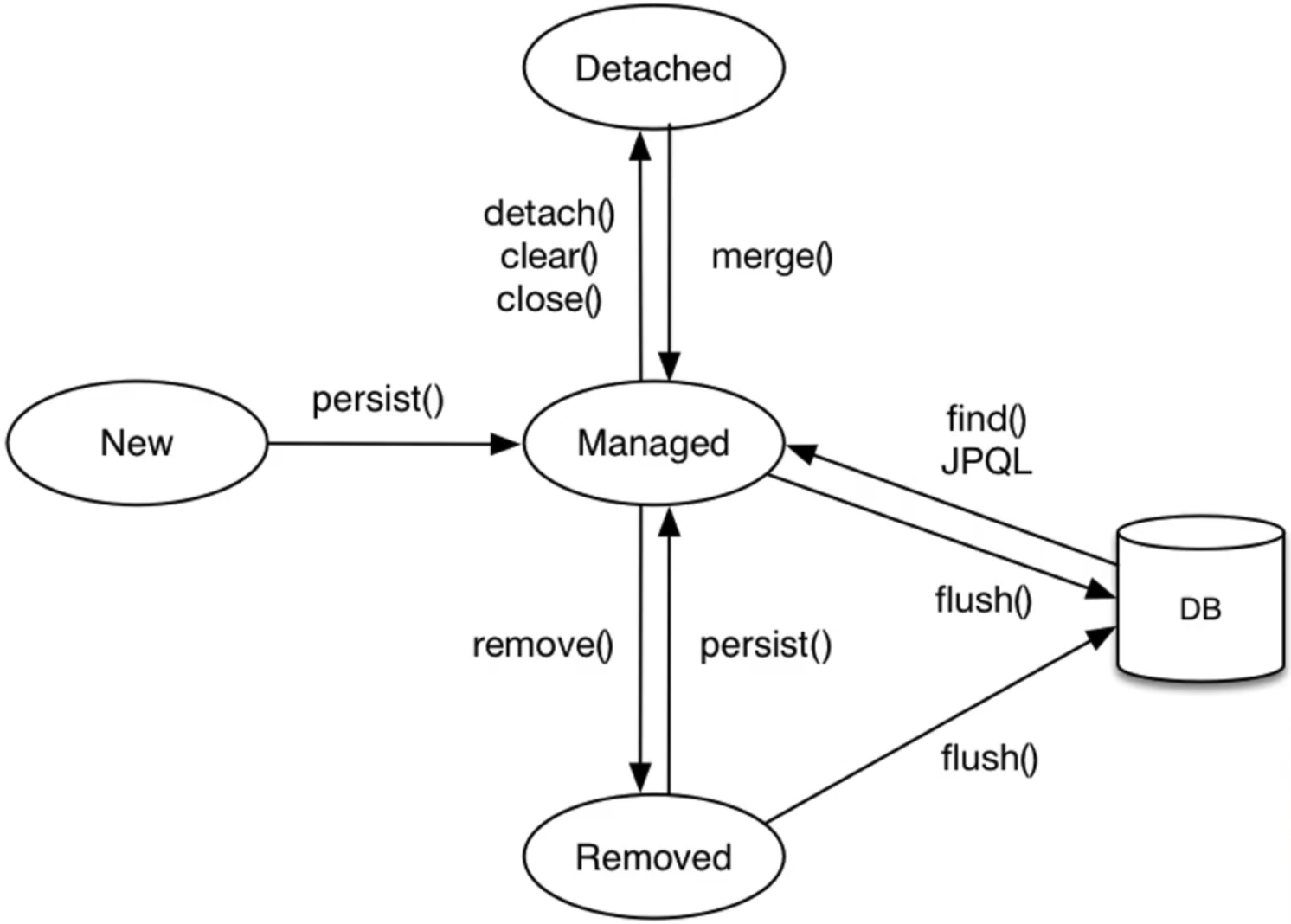
사진 출처 : 인프런 김영한 강사님 - JPA 기본편1
-
new/transient- 비영속 상태 : 객체를 새로 만들고 아무것도 안한 상태.Persistence Contect와 아무런 관련도 없는 상태이다.Member member = new Member("Kim Jae Jun", 26);객체만 생성하고 아무것도 안한 상태의
member는 비영속 상태이다. -
managed- 영속 상태 :Persistence Contect에 관리되는 상태.Member member = new Member("Kim Jae Jun", 26); em.persist(member); // member 객체를 Persistence Context에 저장한 상태(영속 상태)주의) 현재
em.persist(member)이 때 DB에 저장되는게 아니다. -
detached- 준영속 상태 :Persistence Contect에 저장되었다가 분리됨 상태. -
removed- 삭제된 상태 :Persistence Contect에서 삭제된 상태.
다음 포스팅에서는 JPA의 몇가지 기술에 대해 상세히 알아보도록 하겠다
Reference
JPA 역사, MyBatis, JDBC, JPA, ORM이란(Tecoble Youtube)