on
DB Normalization(정규화)
DB Normalization(정규화)
DB 정규화에 대해 알아보자
Normalization이란?
- data의 중복과 적절하지 않은 INSERT, UPDATE, DELETE anomaly를 제거하는 DB 설계 기술.
- Normalization 큰 table에서 작은 table들로 나누며 나눠진 table들을 relationship으로 연결하는게 규칙이다.
Why? 왜 정규화를 할까?
Data의 중복에 대해서는 쓸모없는 공간을 낭비 안하겠다는 생각은 이해가 간다. 중복 말고는 정규화를 하는 이유가 없을까?
바로 위에 적혀있는 anomaly 한 상황 때문이다. 데이터의 중복을 제거했어도 우리는 데이터가 저장되어 있는 데이터베이스에 읽기/쓰기/삭제 등과 같은 작업을 수행해야 할 것이다. 그 때 중복된 데이터 때문에 잘못된 수정/삭제/삽입 연산이 발생한다면 데이터베이스는 integrity와 consistency 를 지켜지 못하게 될 것이다.
Data integrity and consistency
- Data integrity : data의 전체 life cycle에 걸쳐서 data의 정확성과 일관성을 유지하고 보장하는 것
- Data consistency : 서로 다른 장소에 보관된 동일한 data가 일치하는지 여부
따라서 정규화가 잘 이뤄지지 않는다면 갱신 이상(anomaly)이 발생할 수 있고, data의 integrity와 consistency를 보장 못하게 만들어서 데이터베이스의 저장된 데이터에 대한 신뢰성이 떨어지게 된다.
SQL에서 정규화의 목적은 중복 데이터를 제거하고 데이터가 논리적으로 저장되도록 하는 것이다. 현재 1~6단계의 정규화 형태가 존재하지만 실제 대부분의 application에서는 제 3정규화 까지만 이뤄진다고 한다.
제 1 정규화(1NF : First Normal Form) Rules
-
Rule 1 : 각 table의 attribute는 값으로 1개의 값만을 가져야 한다.
→ relation에 속한 모든 attributes의 값이 원자값으로만 구성되어 있어야 한다는 것.
-
Rule 2 : 각 저장값(row)는 unique해야 한다.
따라서 쉽게 말하기 위해 참조한 사이트의 데이터베이스 테이블을 예시로 보도록 하자.
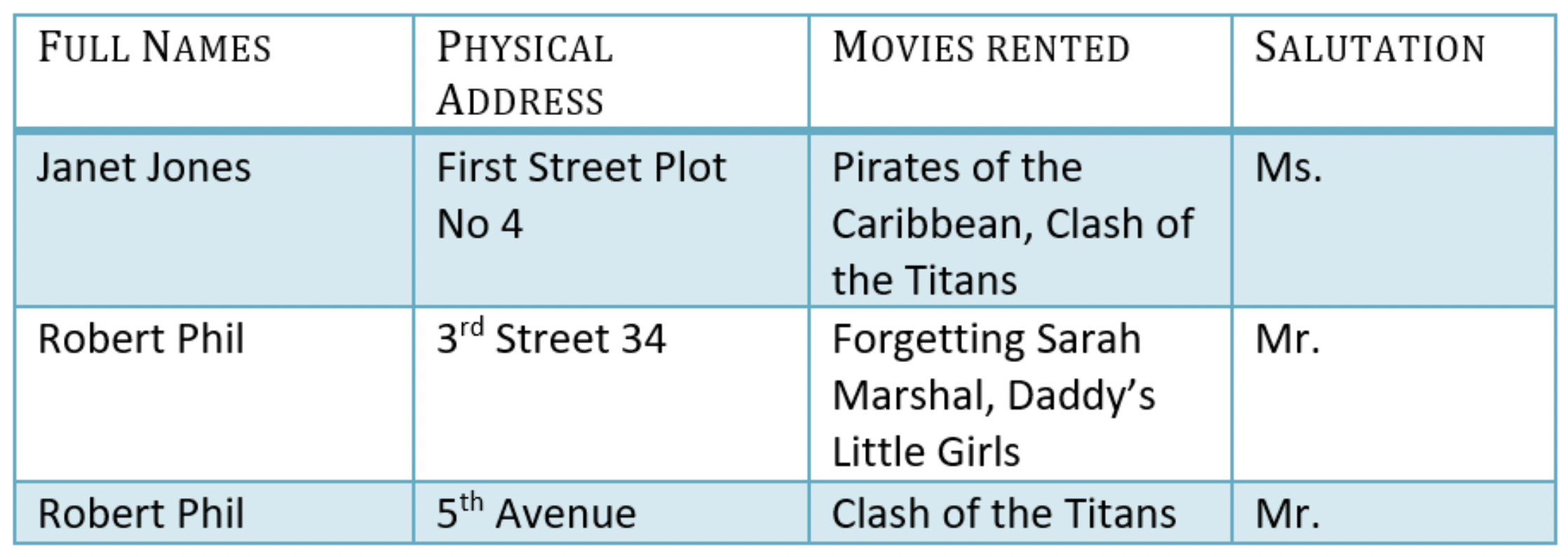
Movies Rented column을 보도록 하자. 현재 1개의 column(1개의 attribute)에 여러개의 주소가 ‘,’로 구분되어 존재하는 것을 볼 수 있다. 이는 1NF를 만족하지 못한 것이기에 다음과 같이 1개의 값으로 테이블을 아래와 같이 바꿔줘야 한다.
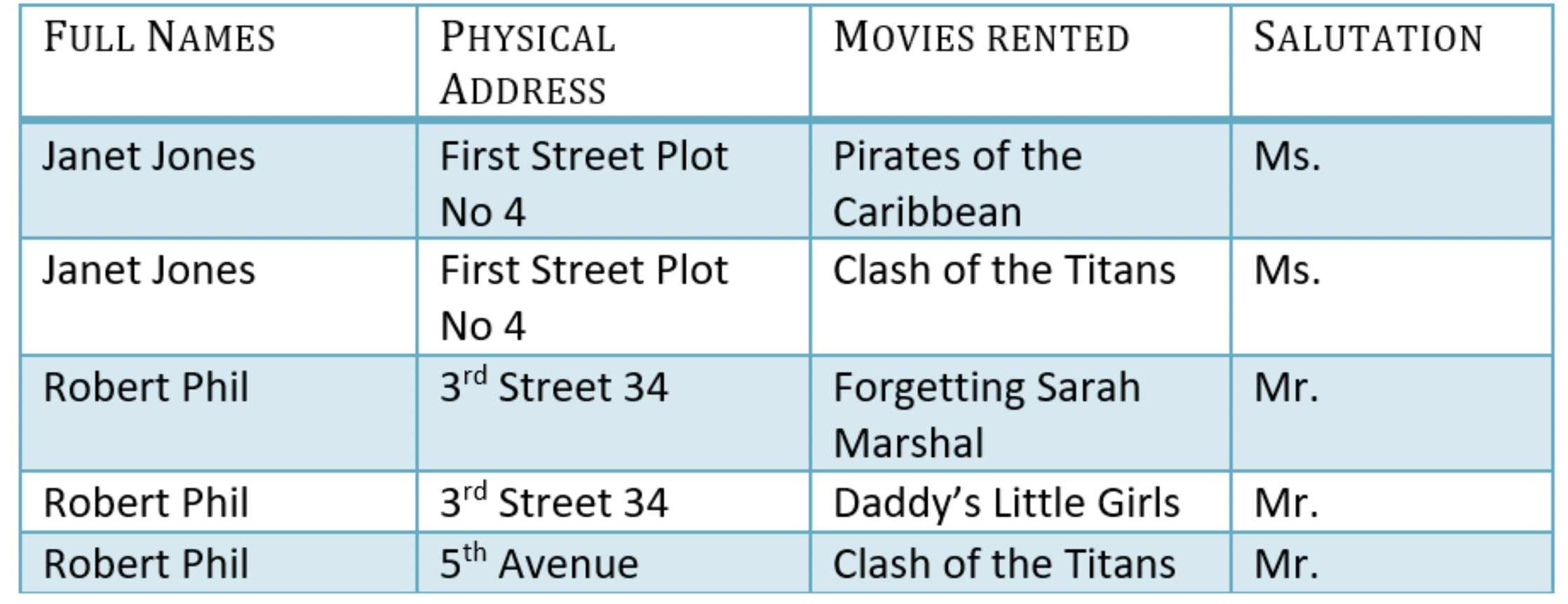
따라서 Rule 1: 각 table의 한 칸은 1개의 값만을 가져야 한다. 를 만족할 수 있다. 그렇다면 Rule 2 는 만족을 시킨 것일까? 결론부터 말하자면 맞다. 왜냐하면 Full Names, Movies Rented 2개의 column이 composite key로써 table에 존재하는 각 tuple을 구별해주고 있다.
근데 Normalization은 데이터의 중복을 방지하는 것이라고 했으나 현재 보다시피… 이름 속성만 봐도 중복이 존재하는 것처럼 느껴진다. 2NF가 좀 더 나은 방향으로의 설계를 제시해준다.
제 2 정규화(2NF : Second Normal Form) Rules
- Rule 1 : 1NF를 만족해야 한다.
- Rule 2 : PK가 아닌 모든 attribute가 PK에 대하여
fully functional dependency를 만족해야 한다.
1번째 규칙은 간단하게도 방금 본 1NF를 만족하면 되는 것 같은데 2번째 규칙이 많이 생소했다. 그래서 functional dependency에 대해서는 여기에 정리를 한 뒤에 다시 정규화에 대한 포스팅을 진행했다. 만약 functional dependency에 대해 모른다면 읽고 오는 것을 추천한다.
바로 예시를 보도록 하자.
위 테이블에서는 현재 아까 1NF에서 봤던 테이블을 2NF를 지키기 위해 2개의 테이블로 나눈 결과이다. member table(1번 테이블)에는 각 row가 unique하는 것을 보장하기 위해서 membership_id 라는 attribute를 추가한 것을 볼 수 있다. 따라서 해당 테이블의 PK는 membership_id 1개이고, 그 외 모든 attribute에 대해서 partial functional dependency 가 아니기에 2NF를 만족하게 되는 것이다. Table2 같은 경우는 2개 attribute가 PK이다.
이걸로 끝난걸까?
2정규화를 했으니 이제 끝인걸까? 맨 처음의 테이블보다는 훨씬 나아졌다. 중복도 많이 없어졌고 별다른 어색함도 찾기 힘들다. 하지만 2NF에서는 다음과 같은 갱신 오류가 발생할 수 있다고 한다. 다음 예시를 보면서 어떤 문제가 발생할 수 있는지 보도록 하자.

현재 위 테이블에서 PK는 학번 이다. 현재 학과전화번호 는 학과 에 의해서 결정되는 정보이다. 근데 학과 는 PK(학번)에 의해 결정된다. 이러한 관계를 transitive functional dependency라고 하는데 2NF에서는 transitive 한 관계 때문에 다음과 같은 anomaly이 발생할 수 있다.
-
update anomaly
여러 학생이 소속된
학과 전화번호가 수정됐을 경우, 그 학과에 속한 모든 학생들의 tuple에서 각각 전화번호를 수정해줘야 한다. 그렇게 안하면 consistency가 유지되지 못한다.-
왜 consistency가 유지 못 되냐?
만약 컴퓨터 공학부 전화번호가 1234-1234 로 바뀌었다고 가정해보자. 당연하게도 DB에 이러한 수정사항을 반영해야 하는데, 위 테이블을 보면, 1번째와 3번째 tuple에서 각각 수정해줘야 함을 볼 수 있다.
-
각각 바꾸면 되지 이게 뭔 문제냐?
만약 위 테이블에 1억개의 tuple이 있다면, 각각에 대해 컴퓨터 공학부인지 확인한 다음 일일이 전화번호를 수정해줘야 한다. 그렇게 해야만 데이터의 consistency가 유지되는데, 만약 개발자의 실수로 단 1개의 컴퓨터 공학과 tuple에 대해서 전화번호를 못 바꾸게 되면 해당 테이블에는 결국 2개의 컴퓨터 공학부 전화번호가 존재하게 되고, 이는 ‘데이터가 같아야 하는데 다른 상황’이 발생하는 원인이 되어 consistency를 유지 못하는 것이다.
그리고 수 많은 데이터에 대해 각각 수정해주는 것 자체도 매우 비효율적이기에 overhead가 클 것이다.
-
-
-
insert anomaly
새로운 학과가 생겼을 경우, 데이터베이스에 추가가 불가능한 문제가 생긴다. 추가하더라도, ‘새로 생긴 학과’에는 ‘학생에 대한 정보’가 없을 것이다. 그렇기에 위 테이블의 PK인 ‘학번’에 어떠한 값도 들어갈 수가 없다. PK는 다음과 같은 성질을 가진다.
- PK (Primary Key)
- Not null
- unique column
- 거의 수정되면 안됨
- 동일한 값 중복 저장 불가
‘학번’에 들어갈 수 있는 값이 ‘새로 생긴 학과’ 에는 없고, PK는 null이면 안되기에 데이터의 추가에 관한 오류가 생긴다는 것이다.
- PK (Primary Key)
-
delete anomaly
위 테이블에서 ‘정보통신공학부’ 에 관한 tuple이 삭제된다면 어떻게 될까? 더 이상 ‘정보통신공학부’에 대한 정보는 존재하지 않게 되는 것이다. 학과에 대한 정보가 삭제됐기에 학과전화번호 정보도 같이 사라졌다.
-
이게 왜 문제? 다시 넣으면 되는거 아닌가?
‘삭제’의 목적에 대해 생각해봐야 한다. 우리는 학과를 삭제하려고 한게 아니다. ‘학생의 정보’를 데이터베이스에서 삭제하려고 했던 것이고, 이는 위 학생 테이블의 tuple 1개를 지우는 행위로 이어진 것이었다. 근데 원래 의도와는 다르게, ‘어떤 학과의 정보 전체’ 가 지금 사라진 것이다.
이렇게 삭제에 대한 오류가 발생할 수 있다.
-
이러한 오류가 발생하는 이유는 2NF는 만족했더라도, 테이블 내에 transitive functional dependent 관계가 존재하기 때문이다. 이러한 관계를 제거함으로써 3NF로 넘어갈 수 있다.
제 3 정규화(3NF : Third Normal Form) Rules
- Rule 1 : 2NF를 만족해야 한다.
- Rule 2 :
transitive functional dependency가 존재하면 안된다.
이전의 2NF까지 진행된 테이블에서는 SALUTATION attribute가 FULL NAMES에 종속되고, FULL NAMES 는 PK에 종속되기에 PK와 SALUTATION 은 transitive functional dependent 한 관계를 가졌어서 갱신 오류가 발생할 수 있었다.
아까 2NF의 처음에 나온 테이블을 다시 3NF에 맞게 나눠 보도록 하자.

테이블을 하나 더 분해하여 transitive functional dependent 한 관계를 제거했다. 이는 더 높은 정규화 형태로 가기 위해 더 이상 분해를 못하는 상태인 테이블이 되었다.
예시로 들었던 테이블이 너무 단순했기 때문인데, 복잡한 DB에서나 다음 단계로의 정규화를 진행하기 위해 시간을 많이 쓴다고 한다. 따라서 다음 BCNF에 대해서만 알아보고 포스팅을 마무리 하겠다.
BCNF(Boyce-Codd Normal Form)
- Rule 1 : 3NF를 만족해야 한다.
- Rule 2 : 모든 determinant가 PK여야 한다.
쉽게 말하면, PK가 아닌 attributes에 대해서는 determinant가 되면 안된다는 것이다. BCNF를 만족 안하는 경우에도 갱신 이상이 생길 수 있다.
공부하고 느낀점
보통 RDB 설계를 할 때에는 위와 같은 문제가 없었기에 정규화라는 개념이 생소했었다. 물론 간단한 프로젝트여서 DB 자체가 복잡한 구조를 갖지 않았기도 했었다. 하지만 JPA강의를 봤어서 그런지 프로젝트를 진행할 때, ‘당연하게 id field를 PK로’ 만들게 됐다. 결국 위와 같은 이론적 배경이 녹아있었겠지만, 실제로 저러한 엄격한 과정을 거치치 않았어도 자연스레 설계를 위와 같은 설계를 할 수 밖에 없다는 생각이 든다.