on
MySQL Index란?!
MySQL Index
개요
Real MySQL 스터디 3주차 8장 인덱스를 공부하게 돼서 정리하는 글입니다.
이전 Record Lock에 대해서 배웠을 때 인덱스는 데이터베이스 성능에 지대한 영향을 끼치고 있음을 알게됐다. 그러한 인덱스는 어떠한 원리로 동작하고, 어떤 자료구조에 값들을 저장하며 쿼리의 결과를 보여주는지 알아볼 것이다.
Disk Read
DB는 우리가 저장한 값을 ‘잘 다뤄주는’ 역할을 하는 것이고, 결국 데이터는 디스크(SSD)와 같은 물리적인 저장소에 저장이 되는 것이다. 따라서 근본적으로 디스크에서의 물리적인 Read 시간이 DB Read에서의 대부분일 것이기에 간단하게 디스크 I/O에 대해 알고 넘어갈 것이다.
Disk I/O speed
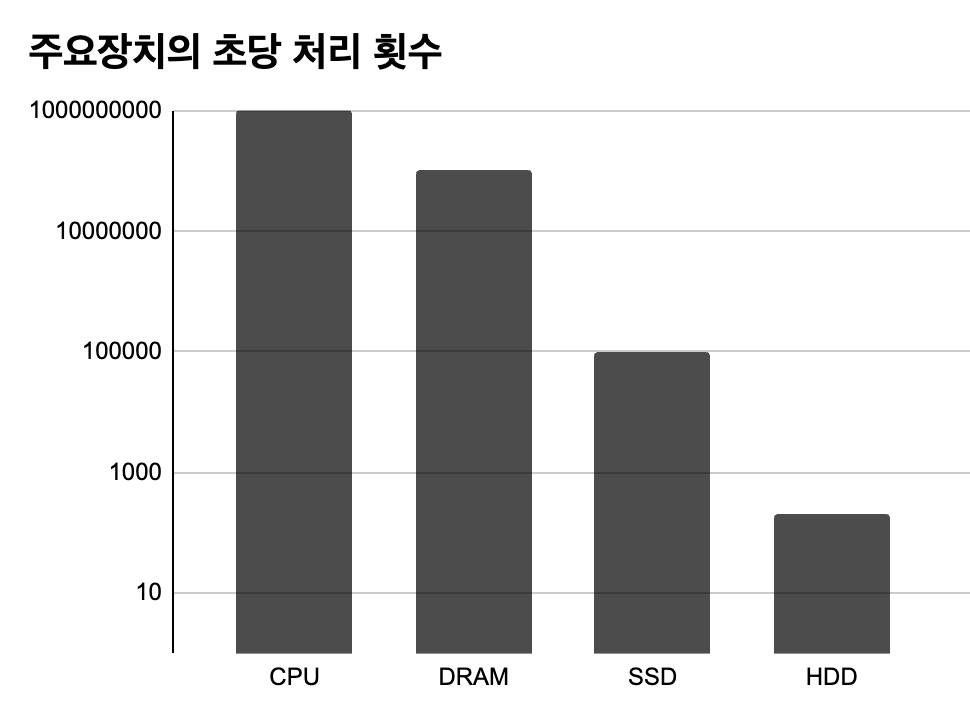
위 그림은 책에서 제공하는 초당 처리 횟수 정보를 나타낸 것이다. (Google spread sheet로 차트 만드는게 개발보다 어려운 듯…)
CPU가 가장 빠르고, 그 다음으로 RAM과 저장장치(디스크)가 따라오는 것을 볼 수 있는데, 중요한 것은
“디스크 처리 속도는 메모리 처리속도에 비해 1000배 정도 느리다 라는 것”
SSD여서 그나마 1000배지, 예전 기준으로는 HDD만 있었을 시절을 떠올리면 거의 10만배 정도 차이가 난다. 최근에는 어차피 SSD를 다 사용하고 있을 것이기에… 이렇게 비교하는 것에 의미는 없을 수 있지만, 이 다음으로 얘기할 Random I/O, Sequential I/O를 말할 때 필요하기 때문에..
Random I/O vs Sequential I/O
둘 다 디스크의 헤더를 움직여서 해당 위치에 접근한다는 것에 있어서는 둘 다 같다. 차이점은 아래와 같은데,
- Random I/O : 랜덤한 위치에 기록이 존재할 경우, 찾기 위해서 N번의 system call 필요.
- Sequential I/O : 순차적인 위치에 기록이 존재할 경우, 찾기 위해서 1번의 system call 필요.
현재 차이점만을 봤을 때에는 단순하게 Sequential I/O가 Random I/O에 비해 N배 가량 빠르다. 그렇기에 Random I/O의 경우가 더 많은 리소스가 필요하다. (얼마나 랜덤한지에 따라서 발생하는 차이가 달라질 것이다.)
쿼리를 튜닝하여 순차적으로 저장 또는 읽을 수 있는 방법을 찾기란 쉽지 않다. 따라서 우리가 고려해야할 것은 ‘Random I/O를 줄이는 것’이다. 필요한 데이터만을 조회할 수 있도록 쿼리를 잘 날려야 한다는 소리다.
Index
예전부터 인덱스에 대해 공부했을 때 언젠가는 정리를 해야지.. 했는데 그게 1년이 지난 오늘이라니…
이 글을 읽는 여러분과 나를 포함하여 모두가 알고 있겠지만, 나름 포스팅 형식의 글이니 형식상 인덱스에 대해 설명하자면…
“책의 목차”
모든 개발자는 인덱스가 중요하다는 것을 알고, 그렇기에 DB 공부를 시작할 때 transaction과 인덱스를 가장 먼저 보게 되는 경우가 많다.(뇌피셜) 그래서 위와 같이 비유하는 글을 매우 많이 볼 수 있는데, 솔직히 저 말 자체가 담는 의미가 인덱스를 표현하기에 너무 적절해서 그런게 아닐까 싶다.
정리하자면 인덱스란,
- 정렬이된
- 색인(index)
라고 할 수 있다. ‘정렬’에 대해서는 차차 풀어나갈 것 같아서 지금 설명하지는 않겠다.
장점?
인덱스를 쓰면 뭐가 좋을까! 라고 했을 때 역시 ‘읽기’가 빨라진다는 것이다. 앞서 비유했던 것처럼 책의 특정 내용을 보고 싶을 때 ‘목차’를 보고 우리는 원하는 내용을 빠르게 찾을 수 있다. 만약 목차가 없었다면, 우리는 매번 책의 처음부터 끝까지를 읽어야(Full Scan) 할 것이다.
단점?
우리는 DB에서 읽기만 하지 않는다. 쓰기도 해야한다. 책의 목차까지 완성된 상황에서 누군가가 어떤 내용을 넣어달라고 한다면,
- 추가내용을 어디에 넣어야 적절할지 판단
- 책의 목차를 전부 수정 (번호가 기입되어 있던 상황이기에)
- 추가내용을 책의 중간에 추가
라는 과정을 거쳐야할 것이다. 마찬가지로 DB도 비슷한 상황이 발생할 것이기에 DBMS에서 인덱스는 데이터의 쓰기 성능을 어느정도 희생하게되는 것이다.
그리고 인덱스를 걸면 무조건적으로 읽기 속도가 빨라지는 것도 아니다. 극단적으로 인덱스가 너무 좋아버린 나머지, 모든 컬럼을 인덱싱했다고 해보자. 조회할 때 과연 빨라졌을까? 다시한번 현실세계에서 책을 보는 상황을 가정해보겠다.
- 우리가 원하는 내용을 조회하기 위해서 목차를 열람
- 책이 1000 page인데, 목차개수가 1000개라고 해보자.
- 우리가 원하는 내용을 찾기 위해서 1000개의 목차를 모두 봐야한다.
인덱스가 늘어나면 성능이 안좋아진다는 의미가 아니라, 인덱스가 늘어나는 것이 곧 성능이 좋아진다는 것으로 이어지는게 아니라는 말이다.
따라서 우리는 필요한 경우에만 컬럼에 인덱스를 걸어야할 것이다.
인덱스 저장 방식
먼저 용어부터 정리하고 들어가보자.
- Primary Key : record 대표 컬럼. Unique. Not
NULL - Seconary Key : PK가 아닌 나머지 인덱스. (unique index도 포함)
책에서 소개할 저장방식에는 3가지정도가 존재한다.
- B-Tree 알고리즘 : 컬럼의 값을 변형하지 않고 원래의 값을 이용해 인덱싱
- Hash index : 칼럼의 값으로 Hash key 생성하여 조회. 범위 검색 불가.
- R-Tree 알고리즘 : B-Tree 응용
다음 포스팅에서 B-Tree 인덱스에 대해 정리해보겠다.