on
Python-study-3
3주차
3주차 부터는 파이썬으로 간단한 미니 프로젝트를 해볼 것입니다.
Python Web Crawling
우리가 할 이번 프로젝트 주제입니다.
Web Crawling 이란 웹상에 존재하는 정보들을 수집하는 작업을 말한다. - 출처
개발 환경
replit.com에서 하셔도 되고, vscode에서 하셔도 됩니다. 본인에게 편한 것을 사용하세요. 이번에는 2가지 Python module을 쓸 것입니다.
일단 웹 사이트라는 걸 이해해야 한다. 기본적으로 웹사이트는 문서다. HTML이라는 형식으로 쓰여진 문서. - 출처
따라서 우리는 웹 크롤링으로 HTML이라는 형식의 문서를 가져올 것이다.
requests:HTML문서에 담긴 내용을 가져 오도록 request(요청) 하기 위해 필요한 라이브러리.BeautifulSoup4:requests로 요청한HTML문서를 탐색해서 원하는 부분만 쉽게 뽑아낼 수 있는 라이브러리.
라이브러리 설치
이제 위 라이브러리를 설치해봅시다. replit.com에서는 shell에서 진행해주시면 되고, vscode에서는 terminal에서 진행해주시면 됩니다.
~/D-Coder-PythonStudy77$ pip3 install requests
~/D-Coder-PythonStudy77$ pip3 install beautifulsoup4
위와 같이 입력해주시면 됩니다!!
HTML 가져오기
한번 간단한 예시를 보도록 하겠습니다. 아래 코드를 vscode또는 replit.com에 crwaling_Test.py라는 파일을 만들어서 복붙해주세요.
# crwalingTest.py file
import requests
from bs4 import BeautifulSoup
def main():
url = 'https://www.google.com'
html = requests.get(url)
print(html.text)
if __name__ == '__main__':
main()
아마 출력으로 알 수 없는 이상한 글자들이 와르르 나올 것이다.
~/D-Coder-PythonStudy77$ python crwallingTest.py
<!doctype html><html itemscope="" itemtype="http://schema.org/WebPage" lang="en"><head><meta content="Search the world's information, including webpages, images, videos and more. Google has many special features to help you find exactly what you're looking for." name="description"><meta content="noodp" name="robots"><meta content="text/html; charset=UTF-8" http-equiv="Content-Type"><meta content="/images/branding/googleg/1x/googleg_standard_color_128dp.png" itemprop="image"><title>Google</title><script nonce="fOfAVoSQYxjRh+ez78VAhw==">(function(){window.google={kEI:'opLxYObBPOKS0PEP_Zay8Ak',kEXPI:'0,18167,754048,1,530320,56873,954,5105,206,4804,2316,383,246,5,1353,4937,314,6385,1116131,1197754,137,392,302679,26305,51223,16115,28684,17572,4858,1362,9291,3026,4747,12835,4020,978,13228,3847,399,3793,64....(생략)
이상한 문자가 아니라 HTML문서 내용이다. 우리의 코드에서
url = 'https://www.google.com'
라는 것이 있었다. 우리는 구글 홈페이지의 HTML을 화면에 출력한 것이다. requests 라이브러리만으로 HTML문서를 가져온 것이다.
마찬가지로 우리학교의 HTML도 가져올 수 있다. url = '우리학교url'를 대신 입력해보자.
url = 'https://eclass.dongguk.edu/'
~/D-Coder-PythonStudy77$ python crwallingTest.py
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xml:lang="ko-kr" lang="ko-kr" xmlns="http://www.w3.org/1999/xhtml">
<head>
<link rel="shortcut icon" href="/lmsdata/img/common/favicon.ico"/>
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"/>
<script language="JavaScript" type="text/JavaScript">
var mobileKeyWords = new Array('iPhone', 'iPod','iPad', 'BlackBerry', 'Android', 'Windows CE', 'LG', 'MOT', 'SAMSUNG', 'SonyEricsson');
for (var word in mobileKeyWords){
if (navigator.userAgent.match(mobileKeyWords[word]) != null){
parent.window.location.href='MMain.do?cmd=viewIndexPage';
break;
}
}
</script>
<title>동국대학교 이클래스</title>
<meta http-equiv="Content-Security-Policy" content="upgrade-insecure-requests">
<meta name="author" content="메디오피아테크" />
<meta name="description" content="메디오피아 LMS6입니다." />
<meta name="keywords" content="기업LMS, 학교LMS, 온라인컨텐츠개발, LINC관련 사업개발" />
<meta http-equiv="Content-Script-Type" content="text/javascript" />
<meta http-equiv="Content-Style-Type" content="text/css" />
<meta name="viewport" content="width=device-width, initial-scale=1, minimum-scale=1, maximum-scale=1, user-scalable=no" />
</head>
<frameset rows='100%,0%' border='0'>
<frame name='main' src='Main.do?cmd=viewHome' title='Main Frame'>
</frameset>
</html>
동국대학교 이클래스의 주소를 넣으면 이렇게 동국대학교 이클래스의 HTML문서가 출력되는 것을 볼 수 있다.
지금까지는 requests만을 사용해서 url에 해당하는 HTML만 가져왔지만 우리가 알아볼 수 없는 정보들만 가득하다. 우리가 필요한 정보만을 가져오기 위해서 beautifulSoup4라는 라이브러리를 설치했었다. 그걸 사용해보도록 하자.
먼저 우리가 어떤 정보를 찾을 것인지 알아야 한다. 구글 크롬으로 네이버를 열어보자.
- 마우스 오른쪽 클릭
- ‘검사하기’ 또는 ‘검사’ 클릭.
- 오른쪽에
개발자 도구가 뜬다. 거기서 찾을 것이다.
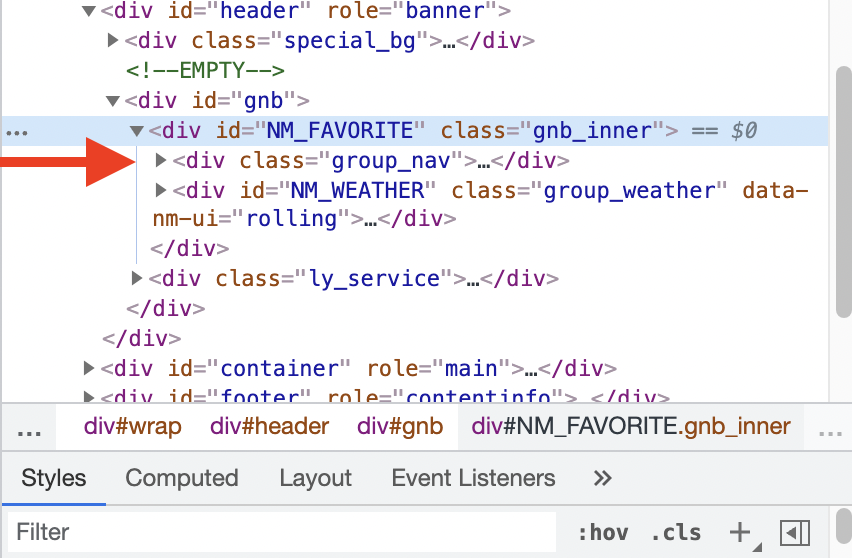
BeautifulSoup4에는 id값을 찾아서 우리가 원하는 HTML을 가져올 수 있다. id='NM_FAVORITE'에 해당하는 HTML을 가져오려고 한다. div에서 id='NM_FAVORITE'이므로 아래와 같이 코드를 작성해준다.
# crwalingTest.py file
import requests
from bs4 import BeautifulSoup
def main():
url = 'https://naver.com/'
html = requests.get(url) # url에 해당하는 HTML내용 가져오기.
soup = BeautifulSoup(html.content, 'html.parser') # 'soup'이라는 객체(object)생성
selects = soup.find_all('div', {'id': 'NM_FAVORITE'}) # find_all() : 해당 조건의 HTML 찾아줌.
for select in selects:
print(select)
if __name__ == '__main__':
main()
~/D-Coder-PythonStudy77$ python crwallingTest.py
<div class="group_nav">
<ul class="list_nav type_fix">
<li class="nav_item">
<a class="nav" data-clk="svc.mail" href="https://mail.naver.com/"><i class="ico_mail"></i>메일</a>
</li>
<li class="nav_item"><a class="nav" data-clk="svc.cafe" href="https://section.cafe.naver.com/">카페</a></li>
<li class="nav_item"><a class="nav" data-clk="svc.blog" href="https://section.blog.naver.com/">블로그</a></li>
<li class="nav_item"><a class="nav" data-clk="svc.kin" href="https://kin.naver.com/">지식iN</a></li>
...(생략)
위의 사진을 보면, id='NM_FAVORITE'아래의 HTML문서가 출력 됐음을 알 수 있다. 하지만 여전히 못알아보겠다. 따라서 우리가 필요한 글자만 추출해보자. get_text()를 쓰면 글자만 추출할 수 있다.
# crwalingTest.py file
import requests
from bs4 import BeautifulSoup
def main():
url = 'https://naver.com/'
html = requests.get(url) # url에 해당하는 HTML내용 가져오기.
soup = BeautifulSoup(html.content, 'html.parser') # 'soup'이라는 객체(object)생성
selects = soup.find_all('div', {'id': 'NM_FAVORITE'}) # 'NM_FAVORITE'이라는 id를 가진 HTML요소 모두 selects라는 배열에 저장.
for select in selects:
print(select.get_text()) # 글자만 출력.
print(len(selects)) # 해당 id가 1개밖에 없어서 배열의 길이는 1
if __name__ == '__main__':
main()
~/D-Coder-PythonStudy77$ python crwallingTest.py
메일
카페
블로그
지식iN
쇼핑
쇼핑LIVE
Pay
TV
사전
뉴스
증권
부동산
지도
VIBE
책
웹툰
더보기
서비스 전체보기
메뉴설정
초기화
저장
25.1°맑음
22.0°29.0°
태평로3가
미세좋음
초미세좋음
태평로3가
1
결과가 나왔는데 빈 공간이 너무 많다. 이를 없애기 위한 방법을 찾아야 한다. 인터넷에 “Python 웹 크롤링 공백제거” 라고 치면 많은 자료가 나온다. 지금은 스터디라서 솔루션을 바로 제공할 것이지만 나중에 본인만의 무엇인가를 만들고 싶다면 계속 찾아보는 자세를 가져야 한다.
strip()함수는 공백을 제거해준다. 이를 쓰면 공백이 그나마 줄어들지만 완벽하게는 줄어들지 않는다. 따라서 내가 해결했던 방법은 replace()함수이다. replace("애를", "얘로 바꿔주세요")처럼 쓰면 된다. 아래 코드를 보도록 하자.
# crwalingTest.py file
import requests
from bs4 import BeautifulSoup
def main():
url = 'https://naver.com/'
html = requests.get(url) # url에 해당하는 HTML내용 가져오기.
soup = BeautifulSoup(html.content, 'html.parser') # 'soup'이라는 객체(object)생성
selects = soup.find_all('div', {'id': 'NM_FAVORITE'})
for select in selects:
print(select.get_text().strip().replace("\n"," "))
print(len(selects))
if __name__ == '__main__':
main()
print(select.get_text().strip().replace("\n"," "))
"""
select에서 text만 가져올거야. 근데 공백은 없었으면 좋겠어(strip()). '\n'와 같은 줄바꿈은 " "로 바꿔줬으면 좋겠어.
"""
~/D-Coder-PythonStudy77$ python crwallingTest.py
메일 카페 블로그 지식iN 쇼핑 쇼핑LIVE Pay TV 사전 뉴스 증권 부동산 지도 VIBE 책 웹툰 더보기 서비스 전체보기 메뉴설정 초기화 저장 24.0°구름많음 22.0°29.0° 태평로3가 미세좋음 초미세좋음 태평로3가
1
이렇게 공백을 제거한 모습을 볼 수 있다.
마무리
이처럼 본인이 만들고 싶은게 생긴다면
- 본인이 필요한 것이 무엇인지 찾아보고,
- 필요한게 무엇인지 알았다면 어떻게 구현할 수 있는지 찾아보고,
- 구현할 수 있는 방법이 있다면 코드를 작성해보고,
- 오류가 생긴다면 검색해보면 된다.
Python스터디 끝났습니다!! 그 동안 따라와주셔서 정말 감사합니다. 제가 이 스터디로 알려드리고 싶었던 것은 스스로 구현하는 방법입니다. 대부분 코딩을 처음 하게 되면 IDE설치조차 힘들어 합니다. 물론 저도 그랬습니다. 누군가 한번만 도와주고 옆에서 알려준다면 더 쉽게 코딩을 할 수 있지 않을까 라는 생각을 많이 해봤기에 부족하지만 여러분들에게 코딩을 처음할 때의 그 장벽을 넘게 해드리고 싶었습니다.
스터디가 끝나고 동아리를 나가더라도 언제든지 질문은 환영입니다. 혹시나 파이썬으로 본인만의 프로젝트를 만들고 싶다 하시는 분들은 얘기해주세요. 도와드리겠습니다.
감사합니다.